
Today we’re open-sourcing Haxl, a Haskell library that simplifies access to remote data, such as databases or web-based services. Haxl is a layer that sits between the application code and one or more “data sources”—APIs for fetching remote data. Haxl can automatically:
- batch multiple requests to the same data source into a single request,
- request data from multiple data sources concurrently, and
- cache previous requests.
Having all this handled for you means that your data-fetching code can be much cleaner and clearer than it would otherwise be if it had to worry about optimizing data-fetching. Head over to the Github repo to check out the code, documentation, and examples. In the rest of this article we describe how Haxl came about, and how we are using it at Facebook.
The story of Haxl
Many services follow a common architectural pattern: on one side there is a set of facts, and on the other is a set of clients that want answers to questions about those facts. In the middle is a set of rules about how to answer particular questions—the real business logic.
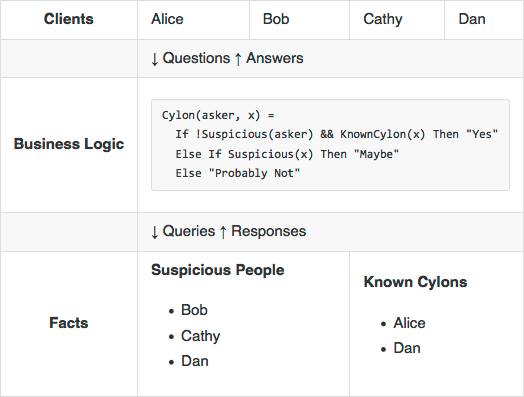
At Facebook, the Sigma service is responsible for classifying different pieces of content. Sigma clients ask high-level questions such as “Is this post spam?” or “Is this URL associated with malware?” and Sigma responds with answers like “Yes, block this account” or “No, carry on”.
Sigma rules are currently written in a domain-specific language called FXL. It connects questions to a dozen distinct sources of facts necessary to answer them, including TAO and Memcached. FXL also serves as a scripting language, insulating rule authors from the underlying C++ implementation of Sigma.
Expressiveness vs. performance
A core problem of a question–answer system is balancing expressiveness against performance. Facts come from diverse sources, so in order to run efficiently, rules must be able to fetch facts concurrently. At the same time, correctness and fast iteration demand that rules be kept free of performance details.
FXL was designed to support this by making all data fetches implicitly concurrent, so that you can write code like:
NumCommonFriends(x, y) = Length(Intersect(FriendsOf(x), FriendsOf(y)))
Here, FriendsOf(x) and FriendsOf(y) are independent, and will thus be fetched concurrently in a single batch. Furthermore, if x and y refer to the same person, FXL will not redundantly re-fetch their friend list.
Unfortunately, FXL’s implementation suffers from other issues: though I/O scheduling is quite efficient, CPU and memory usage are often excessive. We needed a replacement: an embeddable language runtime with strong performance characteristics and safety guarantees, able to express the I/O scheduling behavior we need. And for our purposes, there was only one credible choice.
Haskell to the rescue!
Haskell is a purely functional programming language that is held in high esteem in the programming community for its expressive type system, rich library ecosystem, and high-quality implementations. This combination of properties enables the rapid development of robust software with strong correctness and safety guarantees.
In addition, the Glasgow Haskell Compiler’s high-performance concurrent runtime can be embedded in a C or C++ application, enabling dynamic loading of code that interfaces with the application via Haskell’s foreign function interface.
Enter Haxl
Knowing that Haskell was a viable alternative to FXL, we set about implementing FXL’s I/O scheduling behavior in Haskell as an embedded domain-specific language (EDSL). The result is Haxl (from Haskell + FXL), a library with which you can:
- Make concurrency implicit using Applicative Functors
- Get soundness and modularity for free from implicit caching
- Concurrently fetch data from multiple heterogeneous sources
Let’s go over each of these features in more detail and show some examples of how they’re useful, both individually and in concert.
Implicit concurrency
Revisiting the FXL example above:
NumCommonFriends(x, y) = Length(Intersect(FriendsOf(x), FriendsOf(y)))
The trick that Haxl uses to obtain implicit concurrency is to use Haskell’s Applicative type class. The Applicative concept is related to monads, but its structure allows a computation to be implicitly concurrent. Our example above becomes the following in Haxl:
numCommonFriends x y =
length <$> (intersect <$> friendsOf x <*> friendsOf y)
The <*> operator is where the magic happens; it behaves like function application, but both arguments of this operator can be performed concurrently. If you don’t want to write <*>, we intend to make it possible to use Haskell’s do syntax, so the example could be written like this:
numCommonFriends x y = do
fx <- friendsOf x
fy <- friendsOf y
return (length (intersect fx fy))
Although this relies on a compiler transformation that we haven’t implemented yet.
Using Haskell’s Applicative for concurrency means that certain common Haskell idioms automatically work concurrently when used with Haxl. For example, mapping over a list with mapM becomes concurrent:
friendsOfFriends :: Id -> Haxl [Id]
friendsOfFriends id = do
friends <- friendsOf id
fofs <- mapM friendsOf friends
return (concat fofs)
This works in three stages: first the friends of id are fetched, and then all of the friends of those are fetched (concurrently), and finally those lists are concatenated to form the result.
(Technical note: until the Applicative Monad Proposal is implemented, this works by making mapM = traverse in our library).
Soundness and modularity for free
In the FXL example, we noted that calling numCommonFriends with the same Id twice will perform only one actual data fetch. This is enabled by the caching of all requests to Haxl data sources, and gives us a couple of really useful properties:
- SoundnessDuring the lifetime of a Haxl computation, data in external sources may change. With implicit caching, we can ensure referential transparency: the same request with the same parameters will always return the same result, as long as all data fetching happens through
Haxland notIO.One minor caveat is that requests could be overlapping without necessarily being identical—say, the last 10 and the last 100 posts made by a person. In such a case, it would be possible to observe a changing world. We do not feel this is a significant problem in practice, however it may be addressed in a future version of the library. - ModularityWe want to avoid redundant fetching of data, without any extra deduplication logic at the actual sites of data fetching. Implicit caching leads to a high degree of encapsulation—one call site doesn’t need to know anything about others in order to neatly avoid repeat data fetches; as well as modularity—adding new call sites doesn’t necessitate any changes to existing ones, and still there are no redundant fetches.In addition, since the cache is a record of all queries and their responses, computations can be replayed with a persisted cache and be guaranteed to perform no actual data fetches. This can be incredibly useful to diagnose errors and discover opportunities for increased concurrency.
Heterogeneous Data Sources
Haxl data sources are separated by request type; you may have any number of data sources coexisting in the same Haxl client, and each data source may be used to fetch data of any type. Type safety is enforced through GADTs, so that a request is always paired with its result type; and the Typeable class, so that requests to different data sources can be stored in Haxl’s request store.
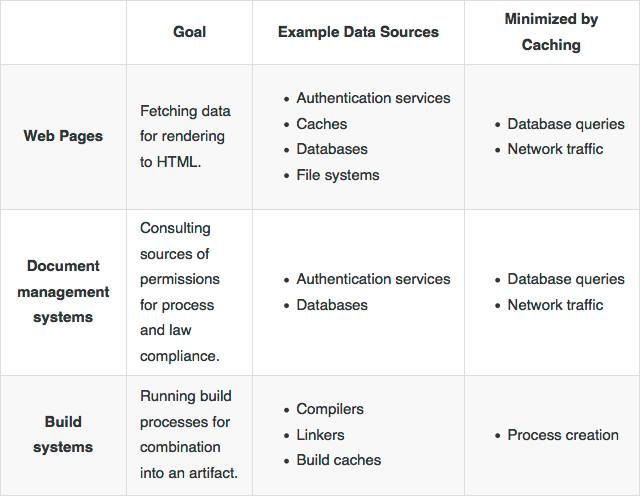
Use Cases
We expect that Haxl will be useful for many business applications:
Thanks to Aaron Roth, Zejun Wu, Louis Brandy, Bartosz Nitka, Jonathan Coens, and everyone else who helped build Haxl.











