
Our Translations app allows users (translators) to click on a phrase as they browse the site, and see the original native string, vote on translations suggested by their peers or contribute their own. Here at Facebook, we offer an innovative approach to web site internationalization that leverages a unique infrastructure and a dedicated user community to keep our interface up-to-date in translation. Phrases can be translated inline and in bulk mode.
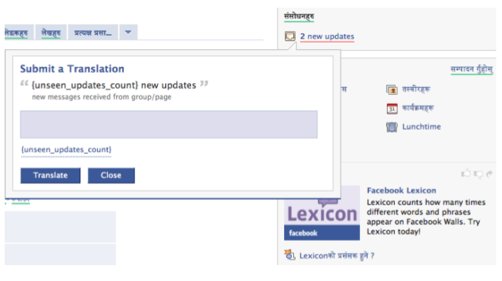
In this process, our users have produced a parallel corpus of more than 4 million phrases in over 90 languages, which is still growing daily. We use {token}s to incorporate dynamic content (including names of users, applications, events, dates and times) so each phrase (template) has “Named Entities” annotated in source and each translation (several per language). This is a valuable resource for research in natural language processing (NLP) and linguistics. On August 7th, I presented some of our ongoing work in “Social (distributed) language modeling, clustering and dialectometry” at a workshop in Singapore. In abstract, “…a scalable implementation of over 250 million individual language models, each capturing a single user’s dialect in a given language (multilingual users have several models). These have a variety of practical applications, ranging from spam detection to speech recognition, and dialectometrical methods on the social graph. Users should be able to view any content in their language, and to browse our site with appropriately translated interface (automatically generated, for locales with little crowd-sourced community effort).”  Translating variable content, represented in tokenized phrases, is problematic because the values (words) need to be inflected in some languages. In our translation architecture, we have several systems in place to facilitate quality and enable correct translations, requiring minimal effort from translators.
Translating variable content, represented in tokenized phrases, is problematic because the values (words) need to be inflected in some languages. In our translation architecture, we have several systems in place to facilitate quality and enable correct translations, requiring minimal effort from translators.
- Glossary, to ensure consistent vocabulary for frequently occurring (and often critical) terms.
- Dynamic Explosion, to separate translation of a single phrase into variants that depend on features of token value.
- Linguistic Rules, to properly handle inflection of variable text (especially difficult for personal names).
Each of these incorporates NLP technology, and is supported by functional and unit testing.
Glossary
Before inline translation, our translator community for a new language must translate and vote on glossary terms. In the main phase of translation, a string might include several glossary terms (e.g., “Connect with your friends by commenting on their actions in News Feed.”, where both “friends” and “News Feed” are glossary terms), each of whose translations should be used in translation of the containing phrase. When a translation is submitted (via the inline dialog in Figure 1), before accepting it, we check for the use of glossary terms. This could be accomplished with a simple string search, but the term might appear inflected in the target language. There are several possible approaches:
- Lemmatize both translation and glossary term; then check (string match) for glossary term stem.
- Exhaustively inflect glossary term; search for each alternative.
- Apply phonological rules to glossary term stem, enumerating effects of possible distinguishing contexts (e.g. in Finnish: open or closed syllable with front or back vowel). This last is a more efficient hybrid, although to implement in a truly cross-lingual fashion requires encoding (or preferably inference) of rules in a collapsed fashion, sensitive to classes of context.
Dynamic Explosion
This technique allows us to split strings on language-specific variations based on translator feedback. For example, a Hebrew translator indicates that in the phrase “{name} wrote on your wall”, the verb conjugation depends on the gender of the subject. Translators can then submit (and vote on) translations for each case: where the actor is male, female, or unspecified. In Arabic, there are different inflections for singular, dual and plural, so in the phrase “number hours ago”, the value of the number affects the translation. Translators can easily see and modify each of these translations, and the appropriate variant is shown to Arabic users (in this case, in their newsfeeds). In order to account for dependencies on token value, we associate variant translations with a bitmask. At render time, the particular value is tested across each dimension in a language-specific set, and the variation bitmask selects the appropriate form for the translation.
Linguistic Rules
Orthographic or phonological rules can affect the spelling of words, and are applied automatically when tokens are substituted with their values. For example, Turkish inflection rules affect any token in possessive, dative or accusative case, such that there are 12 different forms for each. We allow translators to use a proto-form that will be adjusted to match the token when displayed. Specifically, “{name1} wrote on {name2}’s wall” is translated as follows: “{name1} {name2}’(n)in duvarına yazdı” If {name2} is “Malmö”, it will be displayed as “…Malmö’nün…” But if {name2} is “Barış”, it will be displayed as “…Barış’ın…” Our phonological rules system can import rules encoded in standard rewrite-style (including feature-based) or in two-level formalism, and should ideally also handle optimality theoretic constraints, thus easily drawing on extant literature and other data sources for a wide variety of languages.
Future Work
Social natural language processing is (in a sense) in its infancy. We hope to capture aspects of its evolution, just as the field comes to better describe and understand ongoing changes in human languages. We expect more fine-grained analyses to follow, using our framework to compare and contrast a variety of languages (from Bantu to Balinese) and phenomena (inside jokes, cross-linguistic usage of l33t and txt msg terms).
Acknowledgments

David Ellis has drawn on his background in computational linguistics (research in academia and industry) to help build a community-driven translation tool. This technology continues to be developed with support from the i18n team (engineers, language managers, interns and others) at Facebook, and all our international users. If you are passionate about translation, machine learning, or large-scale modeling of dynamic systems on the social graph, try a puzzle or two, and join the geekery.











