
Memcache has been used at Facebook for everything from a look-aside cache for MySQL to a semi-reliable data-store for ads impression data. Of course RAM is relatively expensive, and for working sets that had very large footprints but moderate to low request rates, we believed we could make Memcached much more efficient. Compared with memory, flash provides up to 20 times the capacity per server and still supports tens of thousands of operations per second, so it was the obvious answer to this problem.
The outgrowth of this was McDipper, a highly performant flash-based cache server that is Memcache protocol compatible. The main design goals of McDipper are to make efficient use of flash storage (i.e. to deliver performance as close to that of the underlying device as possible) and to be a drop-in replacement for Memcached. McDipper has been in active use in production at Facebook for nearly a year.
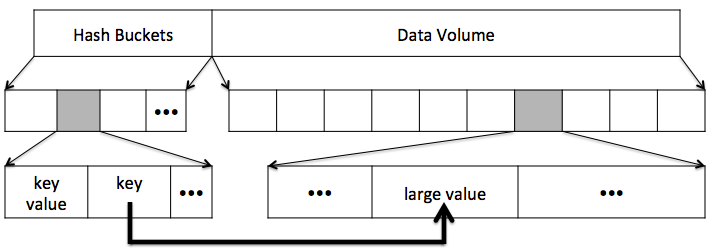
McDipper’s storage layout
All data structures within McDipper are protected with checksums that are verified on every operation. The cache replacement policy is configurable, with a choice of either FIFO (first-in, first-out) or LRU (least recently used). Depending upon your workload, you can enable bloom filters to avoid unnecessary reads, compression to trade computation for capacity, encryption to protect your data should a drive be lost or stolen, and arenas to limit the utilization of storage space by different key classes.
Replacing Memcached
Achieving feature parity with Memcached was unfortunately not as simple as implementing the get, set, and delete operations. There are actually a fair number of issues that come up only when you have a lot of clients talking to many Memcache pools, which are often replicated for durability and performance reasons. One problem to be solved is the race between a set with an old or stale value and an invalidation for the old value.
In general, when you write a new value to the backing store, you need a way to invalidate the old value within Memcached. One way to do this is to simply set the new value to Memcached, but that approach falls over when a value is set twice in quick succession, as the newest value can actually arrive at a Memcached instance before the slightly older one and be overwritten. For that reason, we use deletes to invalidate, and wait for a reader to refill the value when it’s needed. Of course, this approach still has a [far less probable] race, which is illustrated below.
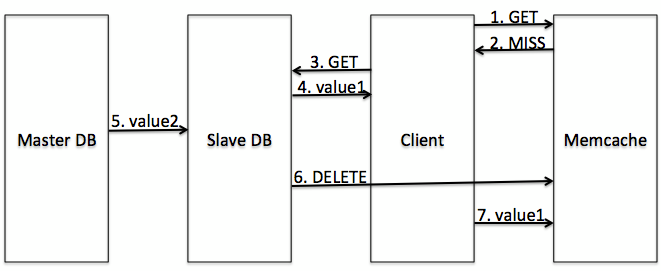
The old set completes after the delete, resulting in a bad value
To deal with that case, we use a delete hold-off, which is a special kind of delete that includes an expiration time. Memcached will prevent any new value from being set for this key until the delete has expired. This means that the stale set will actually need to be issued several seconds after the corresponding delete, which happens rarely enough to have no impact on overall cache consistency.
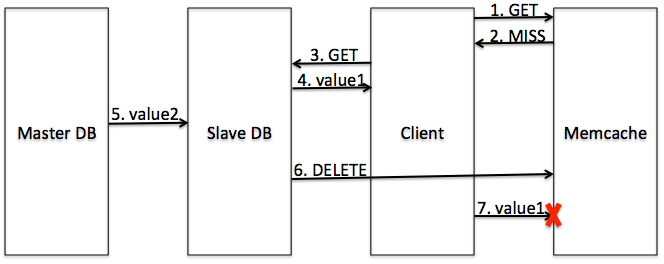
A delete hold-off prevents the tardy set from being executed
In order to implement a delete hold-off, you check for the existence a hold-off and then write the value if none exists. If you do this naively using a get and then a set, you will invariably run into a situation in which the hold-off is created after you check for its existence but before you set the old value. To eliminate this race condition, we needed to implement another method called read-modify-write. This method takes a functional predicate (a function pointer) that maps an old value to a new one. Using this primitive, we were also able to build out the rest of the memcache interface, which provides a number of atomic operations (increment, append, etc.)
Since its development, we’ve deployed McDipper to several large-footprint, low-request-rate pools, which has reduced the total number of deployed servers in some pools by as much as 90% while still delivering more than 90% of get responses with sub-millisecond latencies.
Serving Photos at Scale
Probably the most significant application of McDipper is its use in Facebook’s photo infrastructure for nearly the past 12 months. There are currently two layers of McDipper caches between an end user querying the Facebook content delivery network and our Haystack software, which stores all Facebook photos. HTTP and HTTPS requests to our world-facing HTTP load balancers in our points of presence (small server deployments located close to end users) are converted to memcache requests and issued to McDipper. When those requests miss, they are forwarded to load balancers located at one of Facebook’s photo origins, which have a similar configuration of McDipper instances. Should the origin cache miss as well, the request is forwarded to Haystack.
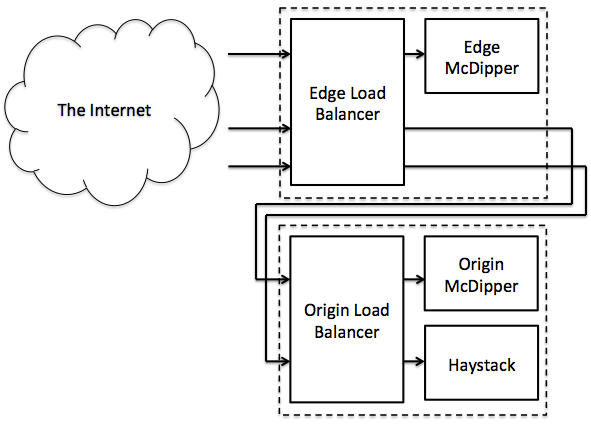
A cache hit, a cache miss-hit, and a cache miss-miss
To optimize for the photos use case, we configured McDipper to run with a relatively small number of buckets sized to hold only indirect records and pin those buckets into memory. We store all of the photos on flash and all of the associated hash bucket metadata in memory. This configuration gives us the large sequential writes we need to minimize write amplification on the flash device and allows us to serve a photo fetch with one flash storage read and complete a photo store with a single write completed as part of a more efficient bulk operation. The use of Memcache protocol allowed us to prototype this approach very quickly using off-the-shelf open source software (nginx + srcache) and we were able to leverage our own existing client software stacks when we moved the client directly into our HTTP load balancer.
We serve over 150 Gb/s from McDipper forward caches in our CDN. To put this number in perspective, it’s about one library of congress (10 TB) every 10 minutes. We do this with a relatively small set of servers, and we’re very pleased with McDipper’s performance on our CDN.
Lessons
Ultimately, we were able to deploy McDipper to a wide variety of applications involving very different sets of constraints. The only reason we were able to pull this off was that we built McDipper to be as configurable as possible. Every new application required extensive study of existing workloads and benchmarks of software/hardware configurations. This approach minimized the number of surprises in production, which is vital when you are trying to build a solid reputation for a new, relatively unproven software stack.
Of course this measured approach wasn’t the only key to our success. McDipper was an effort that took a handful of engineers and an untold number of generous and patient supporters several months to realize. Specifically we’d like to thank our early adopter teams; the hardware provisioning teams who provided us with lots of shiny new servers and racks; and our awesome datacenter team who did all of the leg work of installing the necessary flash hardware. Without their combined effort, McDipper would only be a neat C program.
Alex Gartrell, Mohan Srinivasan, Bryan Alger, and Kumar Sundararajan are engineers on the infrastructure team.











