
This week, 400 engineers from the React community came together for React.js Conf in San Francisco, a two-day conference dedicated to discussing React developer trends while addressing some common challenges to improve the experience for both the developer and the user.
One of the event's highlights came from our very own product infrastructure team here at Facebook. We open-sourced Draft.js, a React-based rich text editor framework that has been in development since summer 2013. This is a new area for us because we've never open-sourced a rich-text framework, but we were excited to see that within the first couple of hours of it being open-sourced in GitHub, Draft.js received more than 1,000 stars. We're thrilled to share that it now has nearly 4,000 stars.
Why rich text?
Rich text is a core part of Facebook products. For instance, within a comment, you might add mentions and hashtags. We highlight those features in blue.
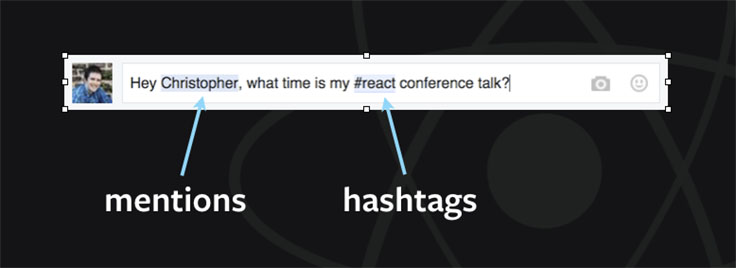
In the past, we've addressed this format with <textarea> and background highlighter <div> tags. However, this solution led to a poor developer experience, with lots of DOM hacks needed to measure text to autogrow the textarea, keep highlighters positioned properly, and track cursor positions with invisible unicode characters. There were also challenges with synchronizing state and DOM, since the plaintext contained no information about the structured mention data. These issues in turn led to poor user experiences, with misaligned backgrounds and broken input. Not only that, but since <textarea> supports only plaintext, we could never expand our feature set to include richer styles or embedded content.
Rich text and React
To resolve the above challenges, we decided to develop our own rich text editor and make rich text input more customizable. Additionally, as we began to build more interfaces with React, we wanted to build a framework that would seamlessly integrate into React applications.
We also needed to identify the right approach for rendering our editor, so we considered a few options. One proposed solution was to draw all contents manually, thus providing complete support for styling and embedded features. A key problem with this approach is the need to manually draw a fake cursor or selection, which would require either more DOM measurement or hacks. Another possibility we considered was to use ContentEditable, a browser widget that often forms the basis for rich editors on the web. ContentEditable is often regarded as confusing, unpredictable, and hard to use, and it directly violates the philosophy of keeping the application state separate from the DOM.
However, we recognized that it offered quite a few positive attributes:
Given the default feature set, we decided to build a controlled ContentEditable React component, following the same control pattern as controlled React DOM inputs. To that end, we wanted to create a framework that would accomplish the following:
Our complete control over the rendered DOM gave us a window into cursor control. We had knowledge of the entire DOM structure at any point, so we could map our selection model directly to a position in the DOM. After rendering updated contents, we could use that knowledge to instruct the native imperative selection API to put the cursor in the correct location. This approach would also allow us to observe selection changes within the editor and map them back to our known model.
An immutable model
Our framework needed a model to represent the full contents and cursor state at any point in time. Additionally, since we were taking control of the ContentEditable DOM, we could no longer depend on the browser to maintain our undo/redo state, and would need to represent it ourselves.
Our approach was to use immutable data structures to represent the editor, with a single top-level immutable object that would serve as a snapshot of the full state. Each snapshot would contain the contents, cursor, undo/redo stacks, and other values needed to represent the editor. This allowed us to provide a simple top-level API with one value to represent the state and one handler to receive state updates from within the editor component, mirroring the controlled DOM input API.
We also made heavy use of data persistence across our immutable snapshots. When one paragraph within an editor changed, every other paragraph would remain untouched. This also meant that within our content snapshots, we could continue to refer to the memory used for the unchanged paragraphs instead of using new memory for unchanged content.

By persisting data in this way, even when creating many snapshots of content state, our memory footprint could remain minimal.
State transitions with immutability
Within undo/redo management, immutability and data persistence become even more useful. If you imagine typing a string of text into a typical native input and then performing an undo action, you will notice that undoing does not mean removing one character at a time. Rather, the entire typed string is removed. Performing an undo action would be as simple as just playing back the previous boundary state.
By identifying common rules and heuristics for spotting these boundary states, we could track which changes to jump to during undo/redo behavior. That meant that any snapshots in between boundary states would become irrelevant and could simply be discarded and garbage collected. Our entire edit history, then, could be represented as a stack of snapshots much smaller than the full set of changes made during the lifetime of the editor, and each snapshot would persist as much data as possible between them.

An added benefit of immutability is the emphasis on performing state updates through purely functional means. Any complex edit operation could be expressed as a composition of smaller, easily testable operations, with no side effects or mutations. A function could accept a state snapshot, create intermediate snapshots, and return a final snapshot with all changes applied. The intermediate snapshots could then be immediately discarded, as only the output would be needed for subsequent rendering, again minimizing our memory footprint.
Open source
When we built this framework, our aim was to help solve rich text composition challenges within Facebook and provide engineers with tools to create new and interesting experiences within their React applications. The editor is now used more broadly in Facebook products, including comment and status update inputs, chat, Facebook Notes, and more.
We feel that this solution has been working well for our products, so we wanted to share the project with the open source community. I announced the launch of Draft.js at the end of my talk at React.js Conf, and have been amazed and encouraged by the response from other engineers at the conference and in the community.
Conclusion
Our goal with developing Draft.js was to provide the building blocks for creating great rich text experiences. It provides the flexibility to customize your editor UI and behavior to meet your use case, and an API designed to help focus your application on data and rendering, not on HTML and DOM.
We want to simplify the process of building interfaces to support rich text, whether that's a few inline text styles or a complex editor for composing long-form articles with embedded rich media.
We're really excited to see what kind of interfaces the community creates next.











