In January 2016, we first launched dynamic streaming, a 360 streaming technology that uses geometry-mapping techniques to stream the highest number of pixels to a person’s field of view. This shrinks the bit rate to a more manageable size that leads to better performance. It allows us to stream 360 video to mobile headset users at 6K — twice the pixels of the industry-standard 4K.
Dynamic streaming delivers the highest-quality experience when it accurately predicts which scene a person will be viewing in a 360 video. For a human, this is a fairly easy task. Years of experience tell us what is interesting to others; we develop intuition for knowing where the action might be.
We wanted to give our system the same ability to intuit the most interesting parts of a video, to help us prioritize where to concentrate the pixels in a stream.
We developed three technologies to tackle this challenge:
- Our new gravitational view-prediction model uses physics and heatmaps to better predict where to next deliver the highest concentration of pixels. Our model improves resolution on VR devices by up to 39 percent.
- We’ve also created an AI model that can intuit the most interesting parts of a video to support prediction for streaming to VR and non-VR devices in the absence of heatmap data.
- We’re testing a new encoding technique called content-dependent streaming that improves the resolution of 360 video on non-VR devices by up to 51 percent, even in low bandwidth.
With these techniques, we were able to create a new encoding system that makes 360 video more accessible under difficult network conditions. In this post, we’ll detail each piece of technology and discuss our approach in developing it. Up first: the gravitational view predictor.
Gravitational predictor: Applying physics to 360 video
Dynamic streaming for 360 video allows us to stream high-quality video only where people are actually looking. To enable this, we have the server apply projection filters to a video to transcode it into streams, with more pixels allocated to different spatial regions of the 360 scene. Using information about the viewing direction, the client then requests that the server send the stream with the highest concentration of pixels in the area being viewed.
Yet, to get the best experience, we shouldn’t choose a stream based on the current view orientation. Like all video-on-demand (VoD) services, 360 video streaming clients will fetch video chunks ahead of playback to preserve smoothness. If the client tries to fetch a video chunk 10 seconds ahead of its scheduled playback time, deciding which stream to fetch ought to be based on the predicted view orientation 10 seconds into the future rather than on the current one.
Because there is so much content in a 360 video, it’s not easy to predict the likely view orientation 10 seconds ahead. But since dynamic streaming was built for VoD, we actually have some advantages on the content level. The Heatmap tool, for instance, signifies the popularity of each spot in every frame of a 360 video. This gives us the information needed to figure out the point of interest (POI) that is most likely to attract people’s attention at each point during the video playback.
However, Heatmap cannot be directly applied for view prediction, due to several properties of 360 video viewing:
- A POI in the video may not be noticed if it is outside a person’s field of view (FOV), so it does not necessarily have an affect on view transition in the future.
- More than one POI can be within a person’s FOV, which makes the future view transition nontrivial.
- There might be no obvious POI within a person’s FOV.
- A person’s kinetic momentum can influence where they look more than the interesting parts of a video do.
To address all these properties in view prediction, we developed the gravitational predictor. The work begins with constructing a landscape for each frame from its heatmap. While the work is actually done in a 3D sphere, the process is best envisioned as if the 360 video were laid out flat. A landscape is constructed by “digging” into that surface. For each point on the map, a kernel whose size is equal to the FOV and amplitude is equal to the heat value (i.e., the popularity of that spot signified on the heatmap) is deducted from the corresponding position on the sphere.
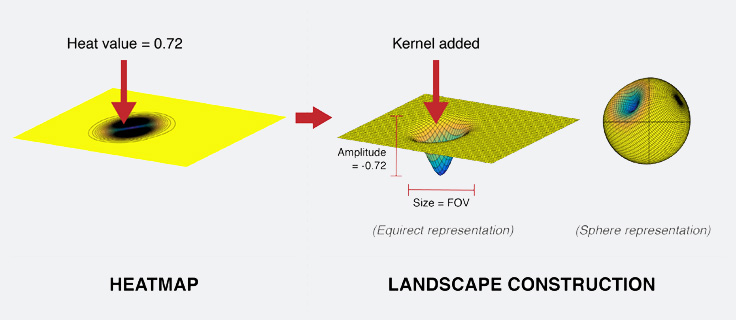
On the resulting landscape, the valleys represent the more interesting regions in the scene and the high grounds represent the less interesting ones. Because the heatmap changes frame by frame, the constructed landscape also changes constantly with time.
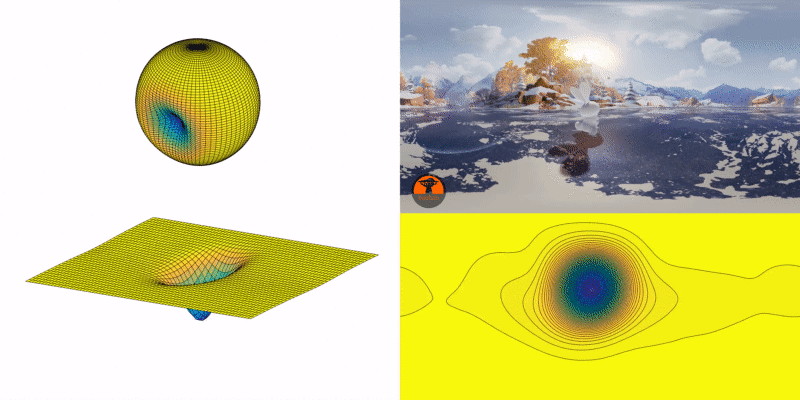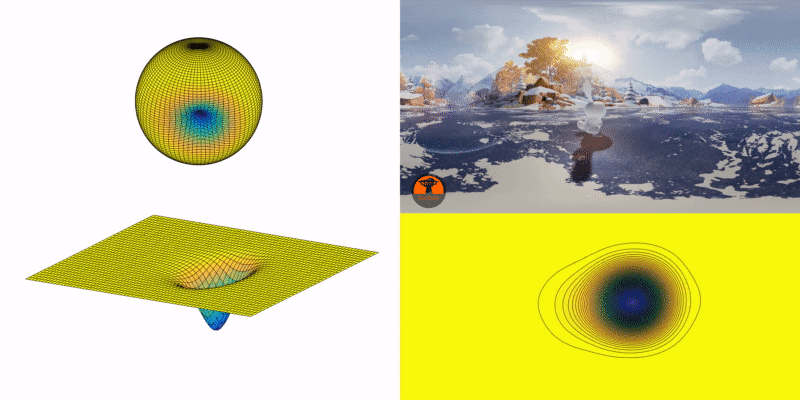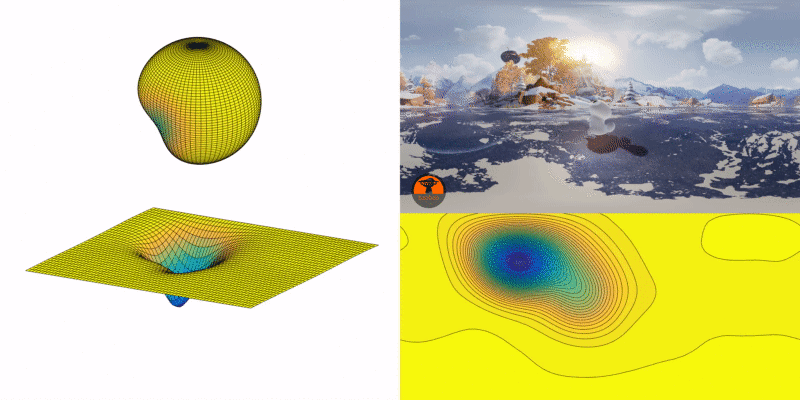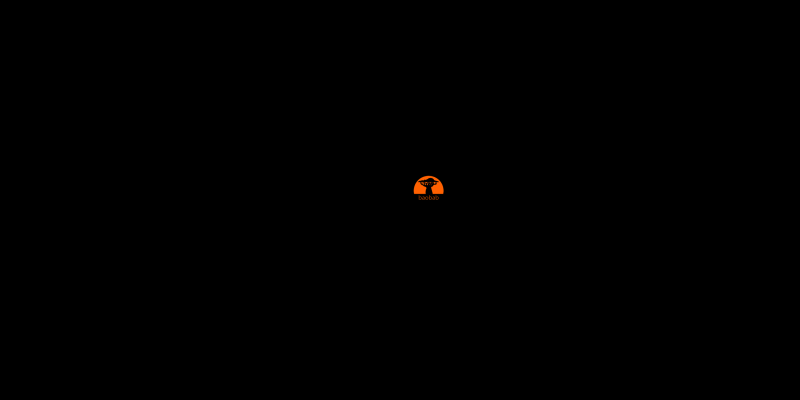
Once the landscape is created, the current focal point resembles a marble on the point of the map where the person is looking, and the marble moves to where most people would look.
How does it move? The marble has an initial velocity defined by people’s view transition speed, and a direction deduced from their views at previous instances. Its movement is affected by the “gravity,” which points toward the center of the sphere.
Using a physics simulator to model prediction
Essentially, the gravitational predictor is a physics simulator of the movement of the marble on the continually changing landscape. Affected by the shape of the landscape, the initial velocity of the marble will be gradually dragged toward the adjacent lower ground (a potentially more interesting region). When the marble is on flat terrain, it means there is no apparent POI within the FOV. In this case, the effect of gravity will become negligible, and the initial velocity will take over and dominate the movement of the marble.
The gravitational predictor addressed four factors we were concerned with in predicting the user’s view orientation in 360 video:
- The influence of POI on the marble is local, and the range of influence is defined by the FOV-size kernel.
- When multiple POIs coexist locally, the predicted movement is determined by their relative interestingness, their distance to the focal point, and the initial velocity.
- When no POIs exist locally, the person’s initial velocity takes over.
- When a person’s kinetic momentum is strong enough, it gives the marble enough initial velocity to run through an undulating landscape — i.e., the viewer’s subjective movement overshadows content saliency.
The balance between the influence of a viewer’s kinetic momentum and the influence of content is tunable by adjusting the gravitational constant (G) in the physics simulation. With a larger G, the influence of content becomes more dominant than kinetic influence. Likewise, with a lower G, the influence of content becomes less dominant.
Generating saliency maps using AI
Understanding which parts of a video interest users is important to the success of the view-orientation prediction.
To address this, we first built a system to generate heatmaps using techniques like computer vision, data filtering and aggregation, and temporal and 3D spatial interpolation to help indicate the areas of most interest.
However, there are two limitations to using heatmaps: scalability and accuracy.
For most videos, we don’t have enough data to generate high-quality heatmaps. This is particularly the case for new videos, and it leaves us without a scalable solution. Second, due to the limitation of the devices on which people are watching the videos, many users have difficulty navigating the regions distant from the video’s default regions. For example, in the screen shot below, most people focus their attention in the center of the frame, which is the default region when they start playing the video. Fewer people look at the regions close to the right boundary of the frame, where the interesting part is happening. This would affect the accuracy of a solution driven primarily by heatmap data.

These are the reasons why we turned to AI.
We decided to build a deep learning system to generate a saliency map for all 360 videos. We trained our deep learning models from scratch, using original videos and behavioral signals as input to our training set. We also experimented with several model structures and cost functions, and built and compared several training and testing infrastructures throughout. The final model is based on a fully convolutional neural network.
The output of the model is a saliency map with different pixel intensities representing different saliency levels. It allows us to provide a scalable predictive solution for videos even in the absence of statistical information, while offering us an option that helps users explore interesting visual content wherever it might be.

We expect that integration and the use of AI-generated saliency maps will make our gravitational models more efficient and ultimately will contribute to higher video quality and better performance.
Content-dependent streaming
Using our dynamic streaming technology, the client switches streams to deliver high-quality video in the direction you turn your head. What if instead of switching to different streams based on direction, we could still deliver high-quality video using a single stream, without knowing where you’re looking?
The answer to this question has led us to develop a new, content-dependent approach to dynamic streaming technology. What ultimately makes this new approach possible is saliency map data offered by AI.
We use a three-step process for every frame of a video:
- Select the view direction. Using statistical data from the saliency map, we can calculate which direction should be amplified.
- Calculate how much we can improve image quality in the selected direction. We think about this as an FOV. For example, if there is only one actor or a single POI in the entire frame, then the quality at that direction can be improved more than the rest of the sphere. But if it is an image of a landscape where every direction is interesting, then we should stream everything with the same quality, so the selected direction will not be amplified.
- Transform the frame based on the selected direction and the calculated FOV. We can transform the frame using off-center cube maps that we talked about earlier this year.
After we process every frame in the video, we get a new video that can be delivered to the client in a single stream. A single stream still gives the high quality in the direction of interest without requiring a client to select streams. We call this content-dependent streaming.
Benefits of content-dependent streaming
A single stream has a bunch of benefits compared with multiple streams:
- A single stream can be buffered, downloaded, and played offline.
- A single stream allows longer video segments and fewer key frames to be transmitted at a time, reducing bit rate and improving compression.
- Because we don’t have to switch streams, there are no resolution jumps (no pop-up effect) and it simplifies the playback.
Now let’s talk about how the client would render this stream.
Playback
To render each frame, a video player needs to know attributes of the frame, including offset length and view direction. On certain platforms, it’s hard or impossible to get an ID or a timestamp for a decoded frame. So instead of worrying about frame synchronization, we embedded the frame metadata directly into a video image. It looks like a colorful artifact in the bottom left corner of each frame. We used three channels (RGB) to embed three bits of data per four-pixel block.

When the video player receives a new frame from a media decoder, it extracts embedded metadata from the image and parses it. Now the player can render this frame with the parameters that correspond exactly to this frame. It solves issues with skipped or dropped frames and simplifies video/rendering synchronization.
Barrel layout
To facilitate content-dependent streaming, we have made significant improvements to the way we manage image layout in order to make the most efficient use of available pixels in each frame.
Previously, we found that the equirectangular layout for 360 video stretches the top and bottom parts of the image horizontally, wasting pixels. This was just one of the reasons we switched to a cube map layout for encoding 360 video. Although the flat faces of the cube map help improve image compression, encoded cube map images lack uniform angular distribution within faces. Notably, the corners of a face have more samples than the center of the face.

We discovered, however, that if we cut the top 25 percent and bottom 25 percent of an image formatted in an equirectangular layout so we’re left with the middle 90 degrees of the scene, we end up with an image that contains a quite uniform angular sample distribution. We can then stretch the image vertically to increase pixel density in the specific area desired.

To cover the rest of the sphere, we can use the top and bottom faces from the cube map layout — in particular, we need only the middle circle of these faces, since they connect to the equirectangular portion of the layout.
Now if we place the equirectangular portion of the image and the two circles from the cube map side by side, the middle 90 degrees of the equirectangular have a pretty nice, uniform angular sample distribution, while the flat top and bottom cube map faces solve the equirectangular issue for the poles.

We call it the barrel layout. For the same surface area, barrel layout has higher pixel density compared with a cube map in the middle 90 degrees. And it compresses better than a cube map for the same texture resolution, since it reuses a lot of data for movements in the horizontal plane.
Horizontal plane offset
Speaking of a horizontal plane, last year we talked about how we apply an offset to a cube map to increase texture quality in a given direction. Overall, it works really well, but the use of an offset introduces additional warping and curves to the image surface.

This hurts compression, because it decreases the amount of data that can be reused when an object in a scene moves. We can address this issue by switching to applying offset to the horizontal plane only. This keeps vertical lines intact. It results in much less warping compared with the uniform offset.

With the combination of the new barrel layout and horizontal plane offset we achieve great compression and improved resolution. With content-dependent dynamic streaming, we can see an increase of up to 51 percent in the effective resolution compared with using cube map and view-dependent dynamic streaming at the similar bit rate. This results in a 6K video playback with a single stream.
The new projection and the horizontal offset are available on GitHub today: https://github.com/facebook/transform360
The updates we’ve shared today, including content-dependent streaming and the integration of both our gravitational and AI prediction models, are currently in testing and will be in production later in the year.











