For years, developers have open()ed a file, write()n to it, then read() from it on a local filesystem. In distributed systems, however, these actions involve multiple processes across different hosts at different places in the network. Each of these hosts — or the network itself — could fail independently and unexpectedly. How should a storage system react, if at all, to such failures? To allow developers to answer these questions, we created an output-input language (OIL), which has a unified namespace and abstraction for files across heterogeneous storage systems. We believe OIL represents a new take on generic storage abstractions. OIL+VCache couples this abstraction with VCache, our distributed virtual memory system, and can provide significant efficiency and performance gains.
Large-scale companies often use many different storage systems, and there is a need to access and share files easily, as well as for files to migrate to different storage systems over time. OIL enables us to configure, rather than code, a composition of heterogeneous storage systems to achieve a desired set of trade-offs. It also expands on POSIX APIs to better capture the nuances of distributed systems. By providing an easy-to-use abstraction that captures these things, OIL can provide substantial benefits, both for those who write applications and for those who write and maintain storage systems.
Developing OIL
Imagine you have an application that is replicating writes to three different hosts. Only one out of three writes is successful. Should the I/O system return “success” to the user — or should it wait for all three to succeed, fail, or time out?

The correct answer to this question depends on the particularities of the application and its required trade-offs. For instance, when video-conferencing with your family, the correct trade-offs are very different from when executing an online shopping transaction. In particular, a videoconference application would likely give up consistency and data loss in exchange for low jitter and low latency, whereas a shopping application would do the opposite.
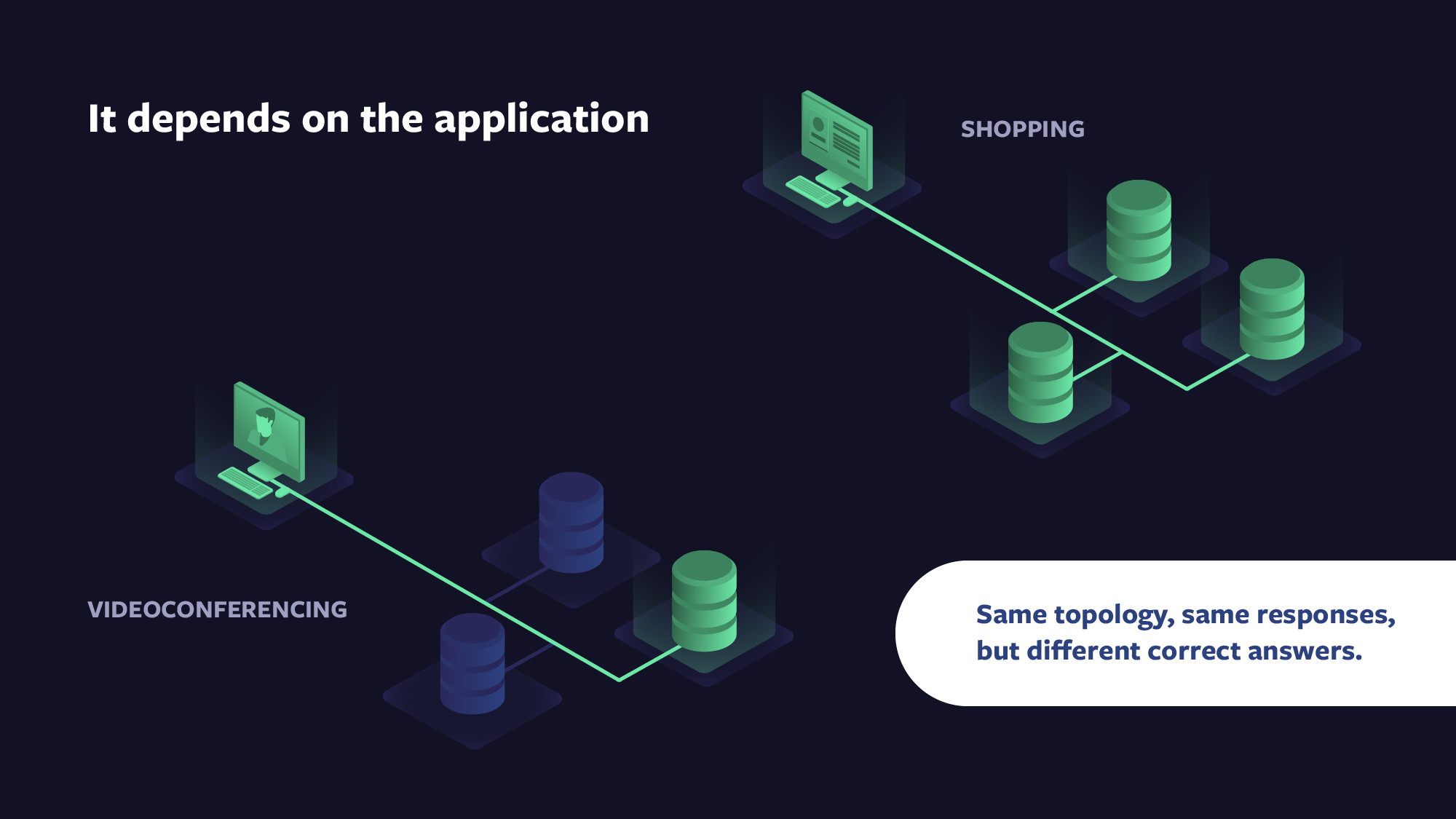 Via composition, each application can use shared storage systems and still select the trade-offs that make sense for the individual application. To accomplish this, OIL stores and understands a directed acyclic graph (DAG), which represents the I/O flow for any file. This DAG allows developers to compose DAGs that allow these properties to change on a per-file or even a per-I/O basis. As needs change, developers can change these properties over time, matching storage properties as appropriate to the use of the file, whether the data is accessed often or rarely, without changing its name. Rather than moving a file from one storage system to another, which causes the name to change, OIL’s virtual filesystem moves with the file, allowing it to keep the same name.
Via composition, each application can use shared storage systems and still select the trade-offs that make sense for the individual application. To accomplish this, OIL stores and understands a directed acyclic graph (DAG), which represents the I/O flow for any file. This DAG allows developers to compose DAGs that allow these properties to change on a per-file or even a per-I/O basis. As needs change, developers can change these properties over time, matching storage properties as appropriate to the use of the file, whether the data is accessed often or rarely, without changing its name. Rather than moving a file from one storage system to another, which causes the name to change, OIL’s virtual filesystem moves with the file, allowing it to keep the same name.
In addition to configuring I/O via DAGs, OIL offers a tweak on the familiar read() API. With most systems, a read for bytes beyond the current end-of-file would generate an out-of-bounds error. OIL, however, would simply have that read() call block until at least one requested byte can be returned or a timeout occurs — even if the requested bytes are beyond the largest written offset or the read is for a range of bytes in the file’s middle, which haven’t yet been written. The implications are surprisingly profound, as files no longer need to be polled for new data. Instead, reading a range of offsets in a file is essentially equivalent to subscribing for that range of offsets. By removing the inefficiencies of polling, we can now create systems that communicate with high efficiency.
Although this capability is powerful, after some real-world deployments, we realized that we needed another tweak. To ensure that I/O on already written files doesn’t incur surprising delays, OIL allows files to be rendered permanently immutable, meaning the file’s bits will never change (though the places where the bits are stored may still change). It also ensures that OIL can quickly return out-of-bounds for any read() beyond end-of-file without delay.
OIL+VCache
Even though OIL empowered developers to compose their I/O across heterogeneous storage systems, we realized we needed more than just the OIL abstraction. Just as virtual memory improves modern operating systems, distributed virtual memory can provide substantive improvements to I/O for distributed systems.
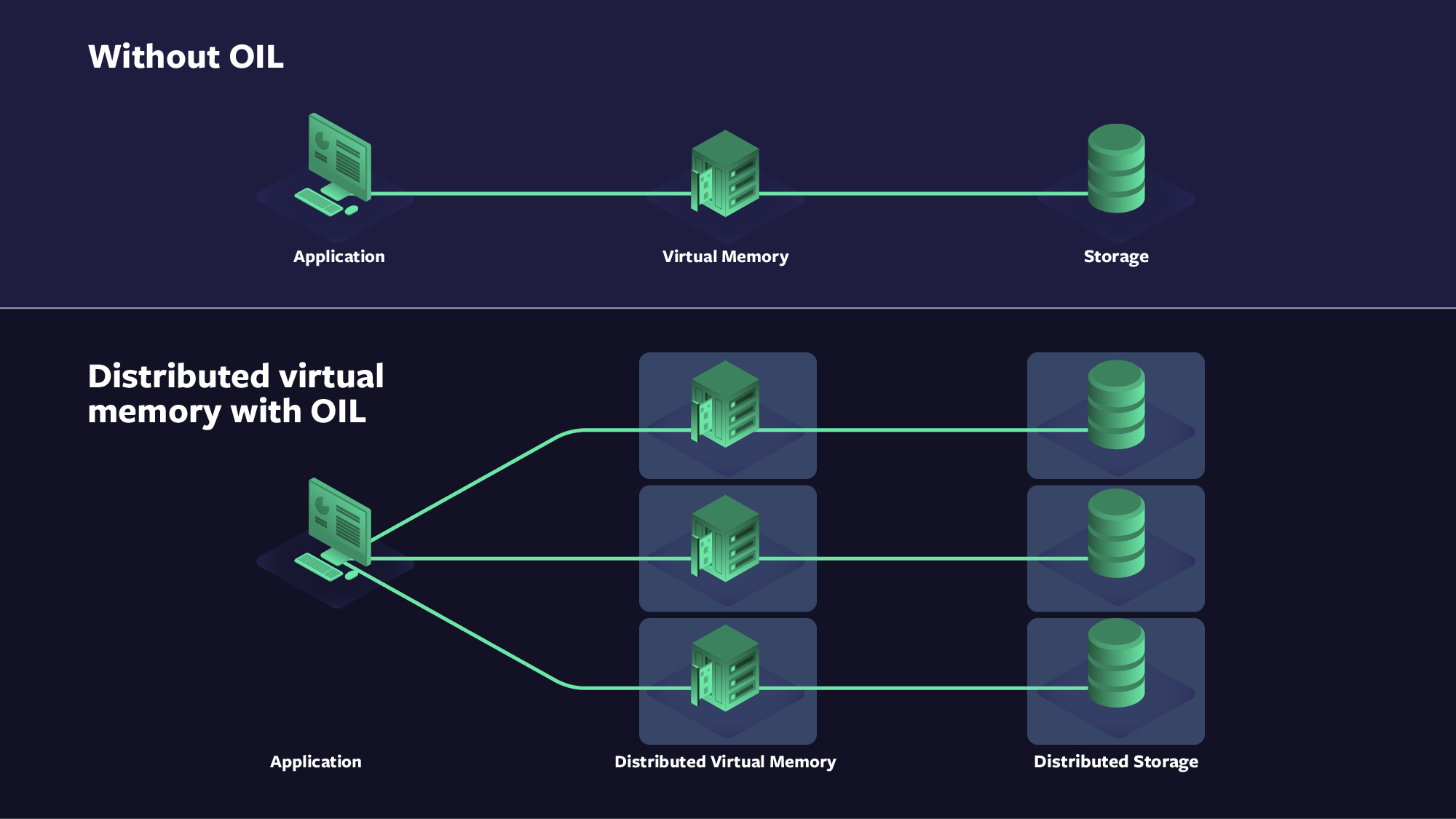
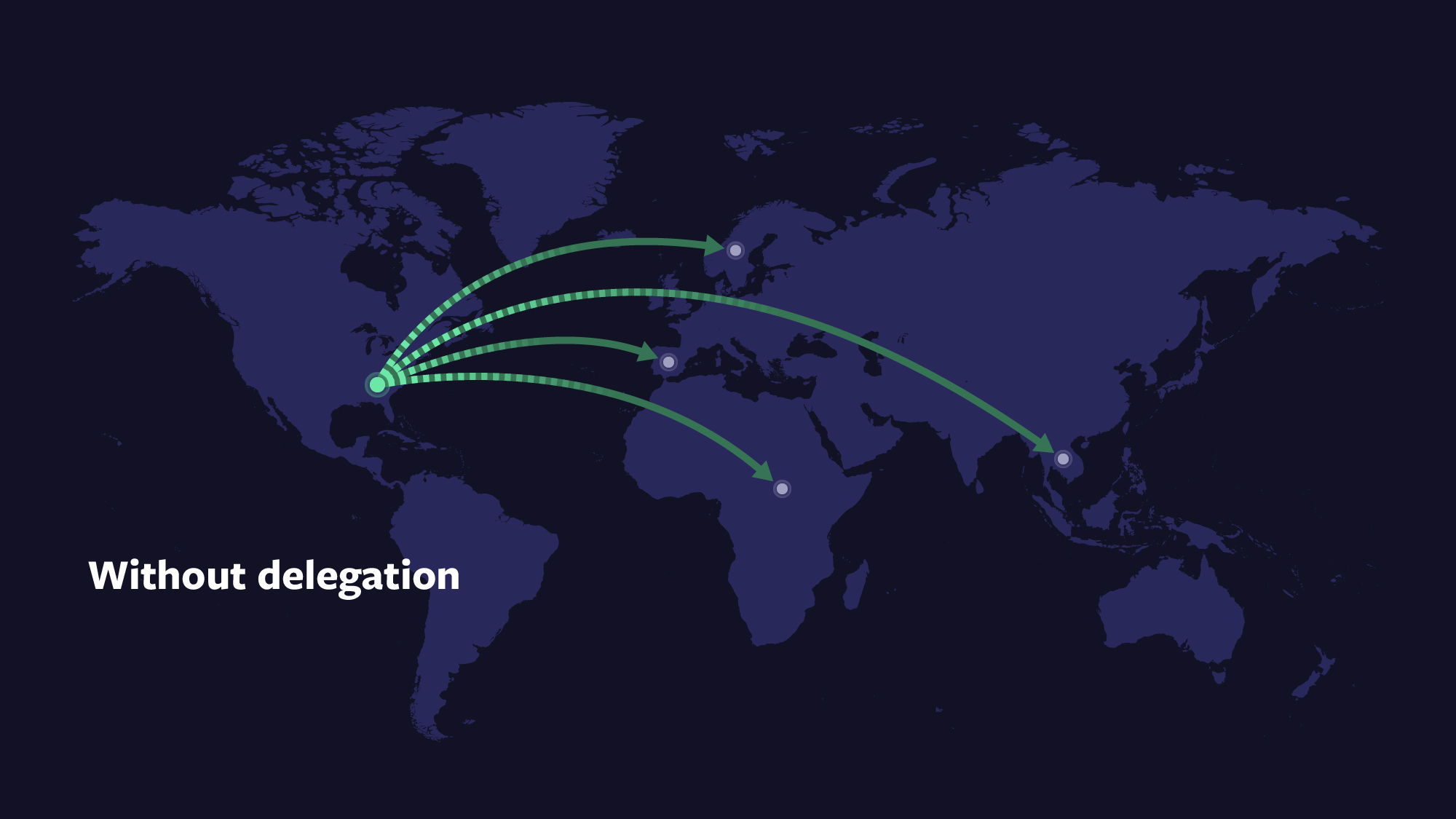
To gain these performance benefits, we created a distributed virtual memory system named VCache. The concept of distributed memory is not new, but VCache distinguishes itself from other such systems with its OIL integration. OIL accesses VCache, then VCache in turn accesses other storage via OIL. Because caches, often in multiple layers, are an essential part of achieving optimal trade-offs, composing storage with VCache (or multiple layers) provides broad benefits. VCache’s presence in multiple user-defined places provides an opportunity for space, speed, and reliability trade-offs at each of those places. VCache supports various write modes including write-through, write-around, and different types of write-back. These modes allow application developers to effectively delegate buffering and rendering data durable to the virtual memory system. Using delegation through VCache nodes, developers can not only optimize where something is stored but can also configure the route taken to get there.
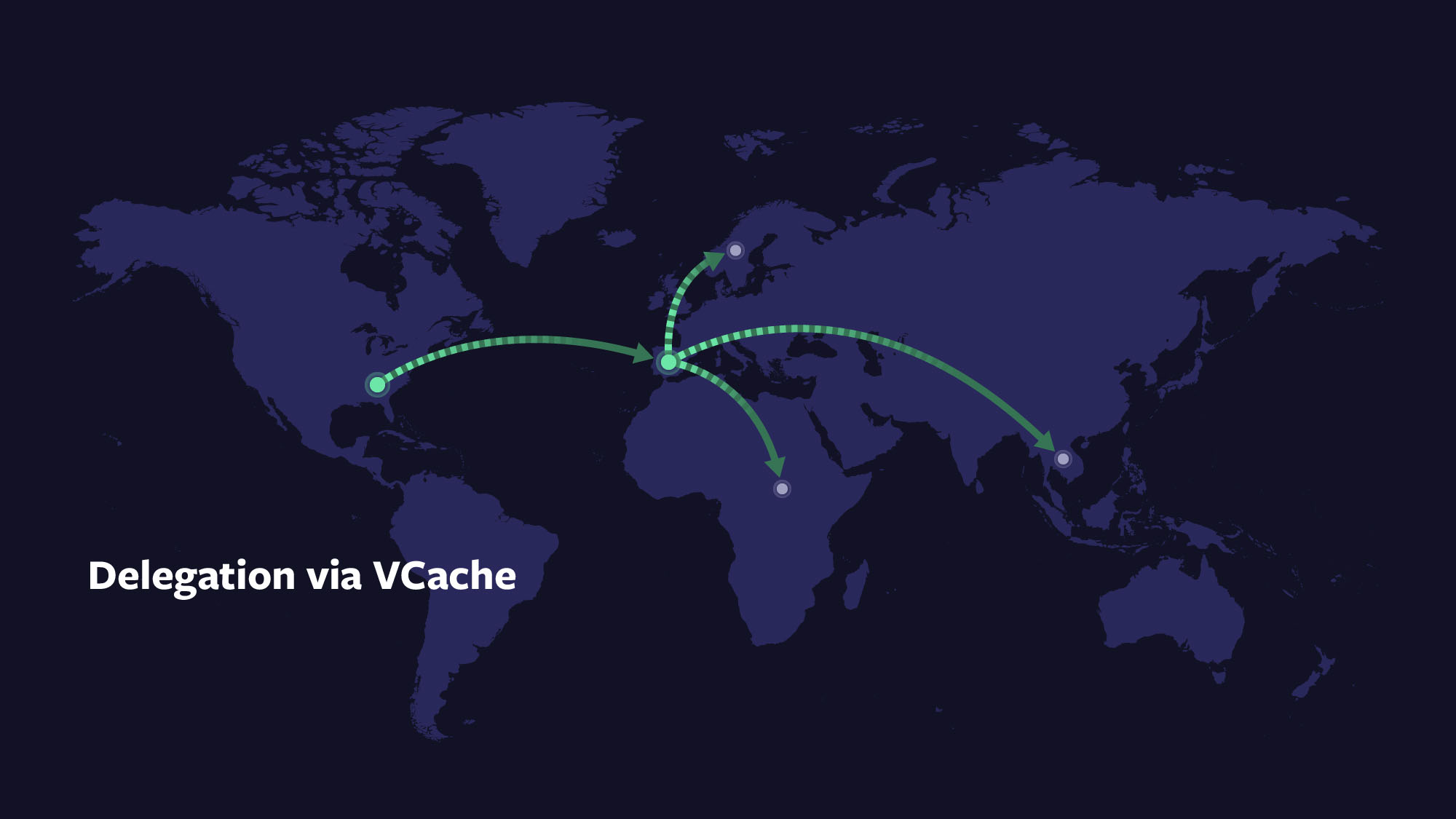
How does OIL+VCache work?
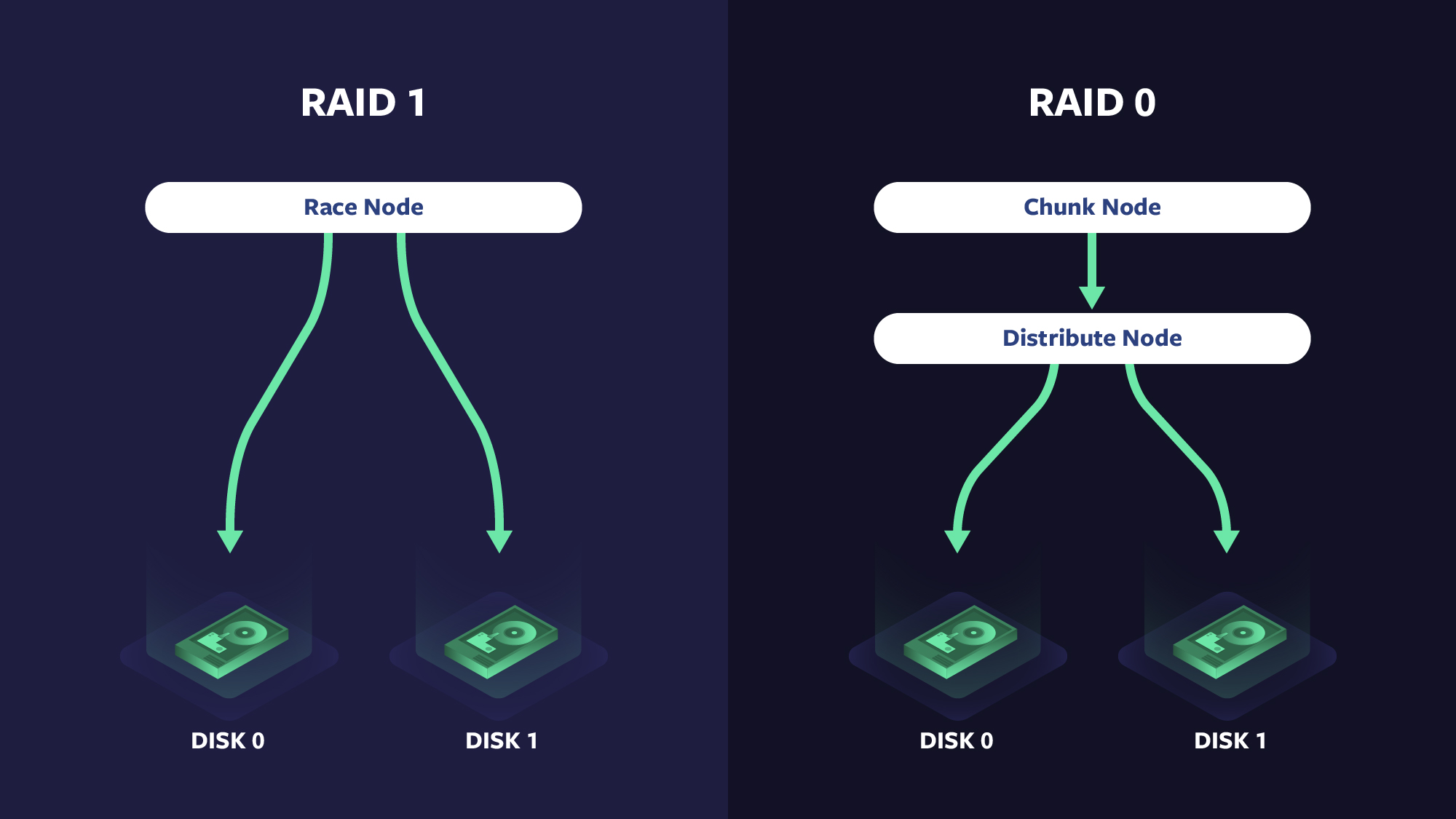
OIL’s DAGs consist of storage modules and race nodes. Storage modules, such as local filesystems or caches, are represented as nodes in a DAG. Each node may have its own configuration specific to its implementation. In addition to passing data to or from the client, DAG nodes may also convey to the OIL framework that they’ve been satisfied and/or exhausted. A stack of data and address-space transforms may be attached to nodes. Some examples of transforms are forward error correction, compression, encryption, and data chunking. The edges between nodes describe properties used when transferring data, such as what quality of service level to set or what protocol to use.
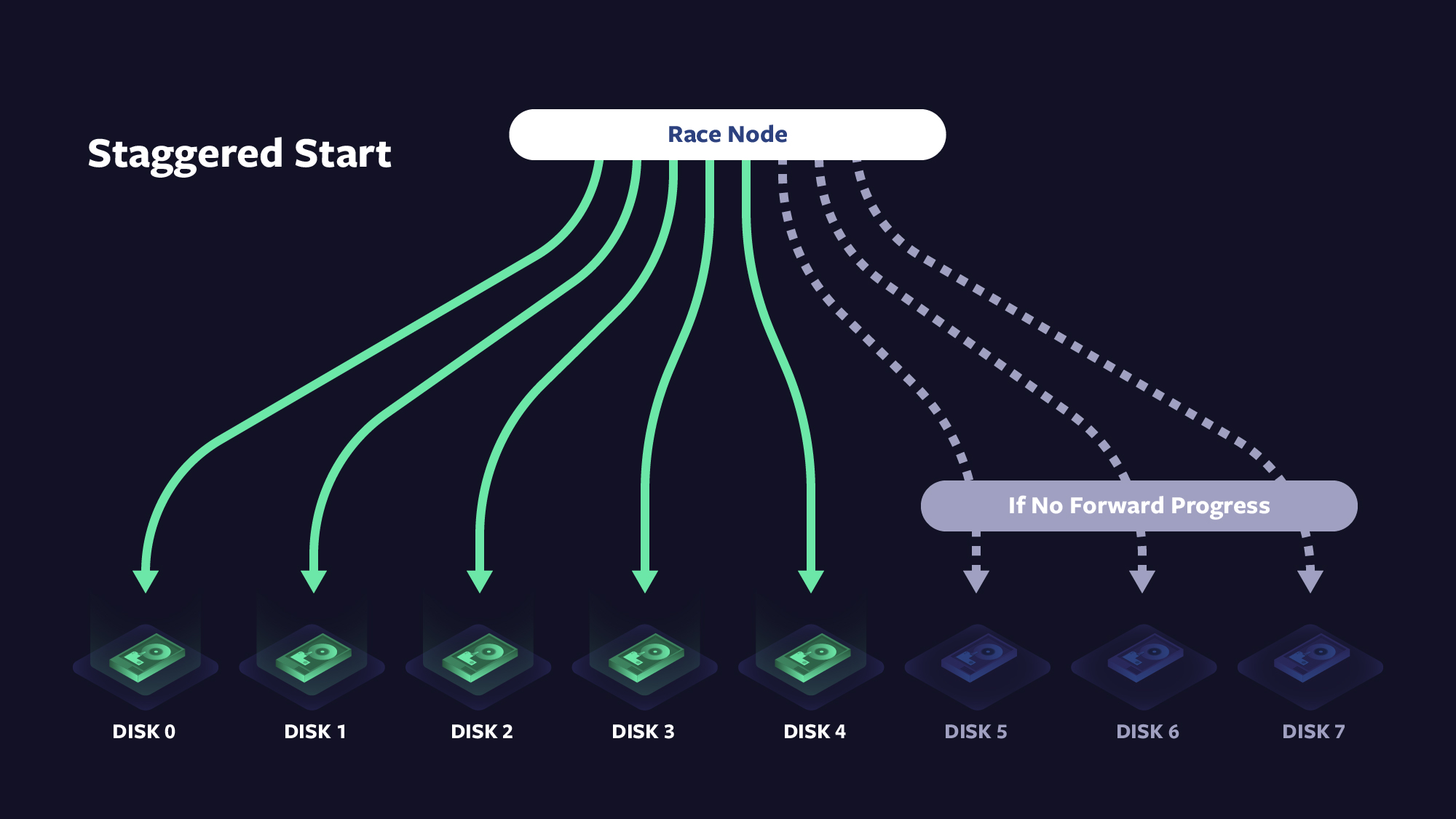
The race node is a built-in virtual node, which can have any number of children. It allows configuration for max concurrency, num-until-satisfied, num-until-exhausted, and staggered-start delay. This node allows the description of control flow for any combination of if-then-else-chain, for-loop, or parallel-for-loop. When num-until-satisfied children have asserted a “satisfied” status, the race-node itself asserts “satisfied” to its parent. When num-until-exhausted children have been executed and assert an “exhausted” status, race itself asserts “exhausted” to its parent. As nodes may optionally assert “satisfied” before asserting “exhausted,” this allows for an unambiguous signaling that the application may make forward progress, separate from signaling that all work for the particular I/O is complete.
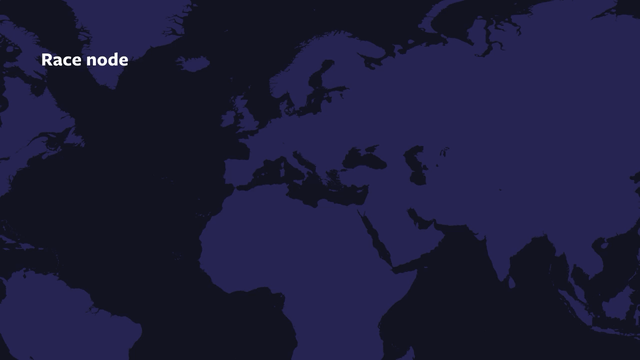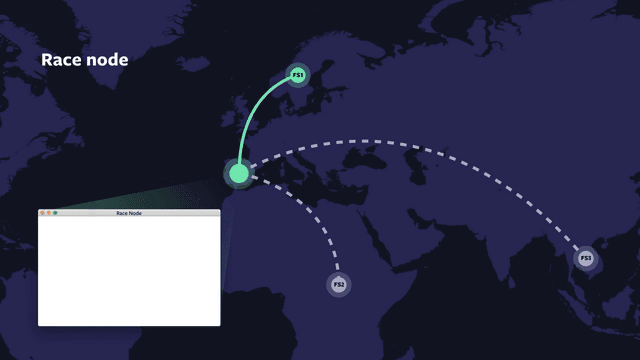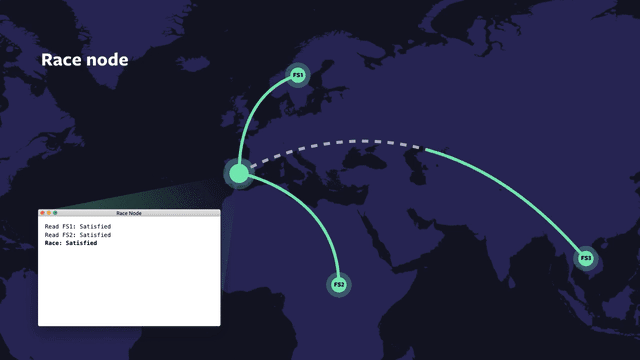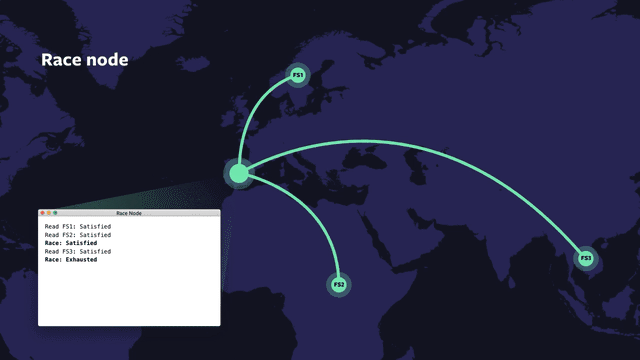
One of the tricky things about asynchronous or delegated writes is that the failure domain of the cache is different from that of the writer’s host. With OIL+VCache, you can have local caches, which share the same fate as the writing host, while also using remote hosts for longer term durability and load sharing. With such hierarchies, you can choose to reduce IOPS and storage systems overhead and still give up relatively few desirable properties such as fate-sharing and lowest latency access to the bytes.
When the sum of the data to be written exceeds the local host memory, however, such local caching will fail. In these cases, if one wished to make forward progress, one must distribute the writes and the data across remote hosts. Because VCache uses OIL as a backing store, and because VCache is available to OIL, one VCache instance can use another VCache instance as its backing store. This means that you can have all of the advantages of host-local memory with all of the advantages of remote memory. Put this together with the race node, and you can control replication, quorum, and shared or separate fate of storage from processing. Below are some examples that illustrate the power of this abstraction:
Because we’re talking about filesystems, we should also be talking about metadata. Metadata typically consists of ownership, ACLs, TTLs, etc. OIL also needs to refer to the data-DAG that describes how, where, and when to do the I/O, so that will also typically end up in the metadata. Metadata has many of the same problems as data in a distributed system; therefore, it makes sense that the DAG abstraction can be reused, and that’s what we do.
OIL allows for the definition of two DAGs — one for metadata, and one for data. The execution framework and structure for these DAGs is the same. The only real differences are that the modules in the metadata DAG give a key:atomic-value interface instead of the data-DAG’s key:byte-stream interface, and that the metadata-DAG is executed before the data-DAG. This separation is purely for convenience, because you could have expressed this in a single DAG. Mutual exclusion, locking, and other serialization is typically described using the metadata-DAG. Describing how one may read and write arbitrary bytes in arbitrary order is accomplished in the data-DAG. The one place where these DAGs differ substantially is that the data DAG can change over the lifetime of the file, whereas it is extremely difficult or impossible to change the metadata DAG without giving up on generic consistency guarantees.
Since it’s been in production, OIL+VCache has enabled enhanced features for live video viewer systems, greater reliability, and lower latency video delivery while reducing computational overhead for storage and other demands. OIL’s flexibility across multiple storage systems provides richer composability options for developers, allowing them to add features that would otherwise be computationally prohibitive. It is our hope that OIL+VCache inspires further innovation of abstractions and APIs across the industry.
We would like to thank everyone who worked on OIL+VCache.