
Editorial note: This post originally appeared on the Facebook AI Research blog.
Progress in science and technology accelerates when scientists share not just their results, but also their tools and methods. This is one of the reasons why Facebook AI Research (FAIR) is committed to open science and to open sourcing its tools.
Many research projects on machine learning and AI at FAIR use Torch, an open source development environment for numerics, machine learning, and computer vision, with a particular emphasis on deep learning and convolutional nets. Torch is widely used at a number of academic labs as well as at Google/DeepMind, Twitter, NVIDIA, AMD, Intel, and many other companies.
Today, we’re open sourcing optimized deep-learning modules for Torch. These modules are significantly faster than the default ones in Torch and have accelerated our research projects by allowing us to train larger neural nets in less time.
This release includes GPU-optimized modules for large convolutional nets (ConvNets), as well as networks with sparse activations that are commonly used in Natural Language Processing applications. Our ConvNet modules include a fast FFT-based convolutional layer using custom CUDA kernels built around NVIDIA’s cuFFT library. We’ll discuss a few more details about this module lower in this post; for a deeper dive, have a look at this paper.
In addition to this module, the release includes a number of other CUDA-based modules and containers, including:
- Containers that allow the user to parallelize the training on multiple GPUs using both the data-parallel model (mini-batch split over GPUs), or the model-parallel model (network split over multiple GPUs).
- An optimized Lookup Table that is often used when learning embedding of discrete objects (e.g. words) and neural language models.
- Hierarchical SoftMax module to speed up training over extremely large number of classes.
- Cross-map pooling (sometimes known as MaxOut) often used for certain types of visual and text models.
- A GPU implementation of 1-bit SGD based on the paper by Frank Seide, et al.
- A significantly faster Temporal Convolution layer, which computes the 1-D convolution of an input with a kernel, typically used in ConvNets for speech recognition and natural language applications. Our version improves upon the original Torch implementation by utilizing the same BLAS primitives in a significantly more efficient regime. Observed speedups range from 3x to 10x on a single GPU, depending on the input sizes, kernel sizes, and strides.
FFT-based convolutional layer code
The most significant part of this release involves the FFT-based convolutional layer code because convolutions take up the majority of the compute time in training ConvNets. Since improving training time of these models translates to faster research and development, we’ve spent considerable engineering effort to improve the GPU convolution layers. The work has produced notable results, achieving speedups of up to 23.5x compared to the fastest publicly available code. As far as we can tell, our code is faster than any other publicly available code when used to train popular architectures such as a typical deep ConvNets for object recognition on the ImageNet data set.
The improvements came from building on insights provided by our partners at NYU who showed in an ICLR 2014 paper , for the first time, that doing convolutions via FFT can give a speedup in the context of ConvNets. It is well known that convolutions turn into point-wise multiplications when performed in the Fourier domain, but exploiting this property in the context of a ConvNet where images are small and convolution kernels are even smaller was not easy because of the overheads involved. The sequence of operations involves taking an FFT of the input and kernel, multiplying them point-wise, and then taking an inverse Fourier transform. The back-propagation phase, being a convolution between the gradient with respect to the output and the transposed convolution kernel, can also be performed in the Fourier domain. The computation of the gradient with respect to the convolution kernels is also a convolution between the input and the gradient with respect to the output (seen as a large kernel).
We’ve used this core idea and combined it with a dynamic auto-tuning strategy that explores multiple specialized code paths. The current version of our code is built on top of NVIDIA’s cuFFT library. We are working on an even faster version using custom FFT CUDA kernels.
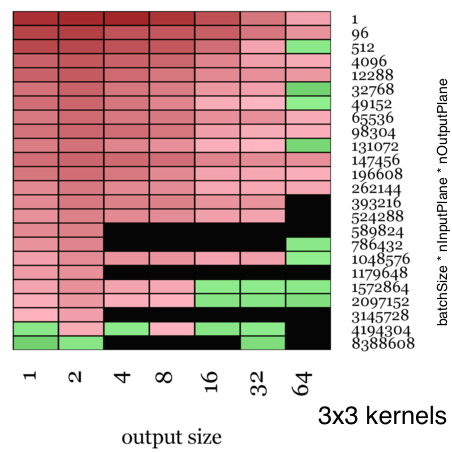
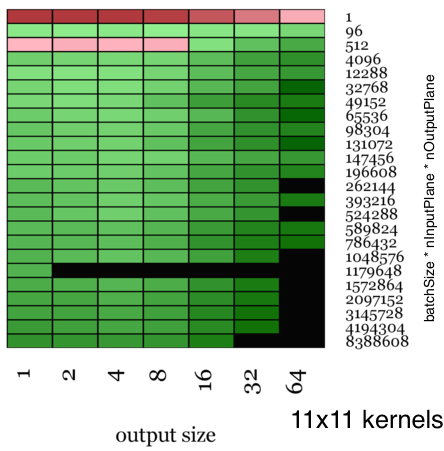
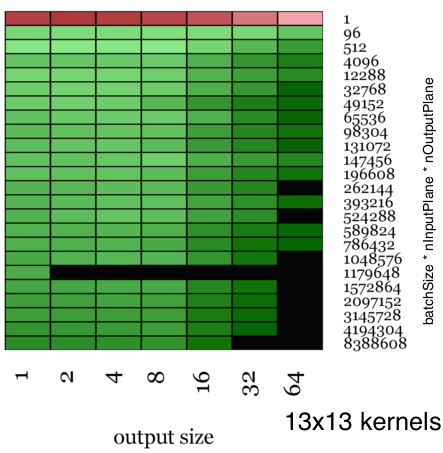
The visualizations shown here are color-coded maps that show the relative speed up of Facebook’s ConvolutionFFT vs NVIDIA’s CuDNN when timed over an entire round trip of the forward and back propagation stages. The heat map is red when we are slower and green when we are faster, with the color amplified according to the magnitude of speedup.
For small kernel sizes (3×3), the speedup is moderate, with a top speed of 1.84x faster than CuDNN.
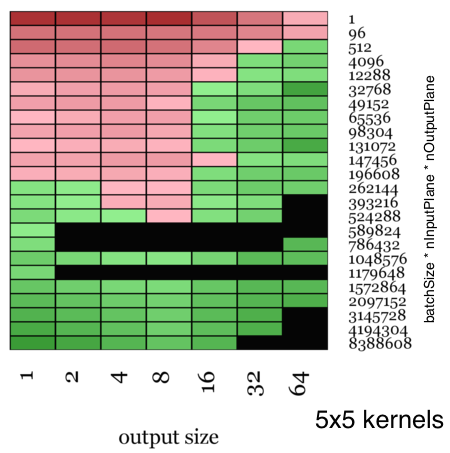
For larger kernel sizes, starting from (5×5), the speedup is considerable. With larger kernel sizes (13×13), we have a top speed that is 23.5x faster than CuDNN’s implementations.
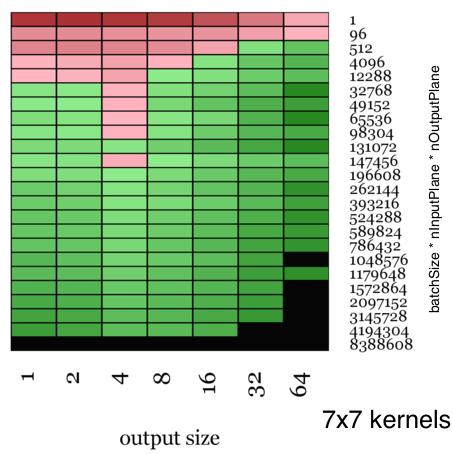
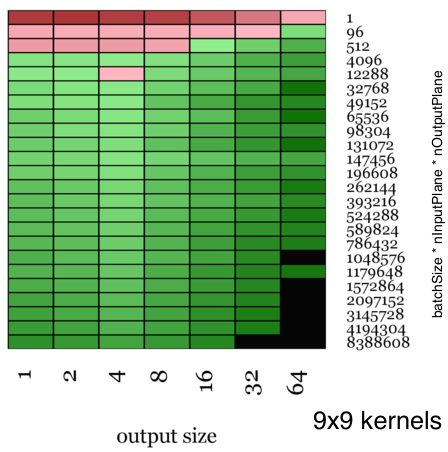
Moreover, when there are use cases where you convolve with fairly large kernels (as in an example in this paper from Jonathan J. Tompson et al, where they use 128×128 convolution kernels), this path is a practically viable strategy.
The result you see is some of the fastest convolutional layer code available (as of the writing of this post), and the code is now open sourced for all to use. For more technical details on this work, you are invited to read our Arxiv paper.
Parallelization over Multiple GPUs
From the engineering side, we’ve also been working on the ability to parallelize training of neural network models over multiple GPU cards simultaneously. We worked on minimizing the parallelization overhead while making it extremely simple for researchers to use the data-parallel and model-parallel modules (that are part of fbcunn). Once the researchers push their model into these easy-to-use containers, the code automatically schedules the model over multiple GPUs to maximize speedup. We’ve showcased this in an example that trains a ConvNet over Imagenet using multiple GPUs.
Links
We hope that these high-quality code releases will be a catalyst to the research community and we will continue to update them from time to time.
To get started with using Torch, and our packages for Torch, visit the fbcunn page which has installation instructions, documentation and examples to train classifiers over ImageNet .
In case you missed it, we just released iTorch, a great interface for Torch using iPython. You can also checkout our smaller releases fbnn and fbcuda, as well as our past release fblualib .
Many people worked on this project. Credit goes to: Keith Adams, Tudor Bosman, Soumith Chintala, Jeff Johnson, Yann LeCun, Michael Mathieu, Serkan Piantino, Andrew Tulloch, Pamela Vagata, and Nicolas Vasilache.











