
To the billions of people using Facebook, our services may look like a single, unified mobile app or website. From inside the company, the view is different. Facebook is built using thousands of services, with functions ranging from balancing internet traffic to transcoding images to providing reliable storage. The efficiency of Facebook as a whole is the sum of the efficiencies of its individual services, and each service is typically optimized in its own way, with approaches that may be difficult to generalize or adapt in the face of fast-paced changes. To more effectively optimize our many services, with the flexibility to adapt to a constantly changing interconnected web of internal services, we have developed Spiral. Spiral is a system for self-tuning high-performance infrastructure services at Facebook scale, using techniques that leverage real-time machine learning. By replacing hand-tuned heuristics with Spiral, we can optimize updated services in minutes rather than in weeks.
A new approach to meet Challenges of scale
At Facebook, the pace of change is rapid. The Facebook codebase is pushed to production every few hours — for example, new versions of the front end — as part of our continuous deployment process. In this dynamic world, trying to manually fine-tune services to maintain peak efficiency is impractical. It is simply too difficult to rewrite caching/admission/eviction policies and other manually tuned heuristics by hand. We have to fundamentally change how we think about software maintenance.
To efficiently address this challenge, the system needed to become self-tuning rather than rely on manually hard-coded heuristics and parameters. This shift prompted Facebook engineers to approach work in a new way: Instead of looking at charts and logs produced by the system to verify correct and efficient operation, engineers now express what it means for a system to operate correctly and efficiently in code. Today, rather than specify how to compute correct responses to requests, our engineers encode the means of providing feedback to a self-tuning system.
A traditional caching policy may look like a tree with branches that take into account an object’s size, type, and other metadata to decide whether to cache it. A self-tuning cache would be implemented differently. Such a system could examine the access history for an item: If this item had never been accessed, it was probably a bad idea to cache it. In the language of machine learning, a system that uses metadata (features) and associated feedback (labels) to differentiate items would be a “classifier.” This classifier would be used to make decisions about items entering the cache and the system would be retrained continuously. This continuous retraining is what allows the system to stay current even as the environment changes.
Conceptually, this approach is similar to declarative programming. SQL is a popular example of this approach: Instead of specifying how to compute the result of a complex query, an engineer just needs to specify what needs to be computed and then the engine figures out the optimal query and executes it.
The challenge of using declarative programming for systems is making sure objectives are specified correctly and completely. As with the self-tuning image cache policy above, if the feedback for what should and should not be cached is inaccurate or incomplete, the system will quickly learn to provide incorrect caching decisions, which will degrade performance. (This paper by several Google engineers goes into detail about this problem and others related to using closed-loop machine learning.) In our experience, precisely defining the desired outcome for self-tuning is one of the hardest parts of onboarding with Spiral. However, we also found that engineers tended to converge on clear and correct definitions after a few iterations.
Spiral: Easy integration and real-time predictions
To enable system engineers at Facebook to keep up with the ever-increasing pace of change, engineers in our Facebook Bostonoffice built Spiral, a small, embedded C++ library with very few dependencies. Spiral uses machine learning to create data-driven and reactive heuristics for resource-constrained real-time services. The system allows for much faster development and hands-free maintenance of those services, compared with the hand-coded alternative.
Integration with Spiral consists of adding just two call sites to your code: one for prediction and one for feedback. The prediction call site is the output of the smart heuristic used to make decisions, such as “Should this item be admitted into the cache?” The prediction call is implemented as a fast local computation and is meant to be executed on every decision.

The feedback call site is for providing occasional feedback, such as “This item expired from the cache without ever being hit, so we should probably not cache items like this one.”
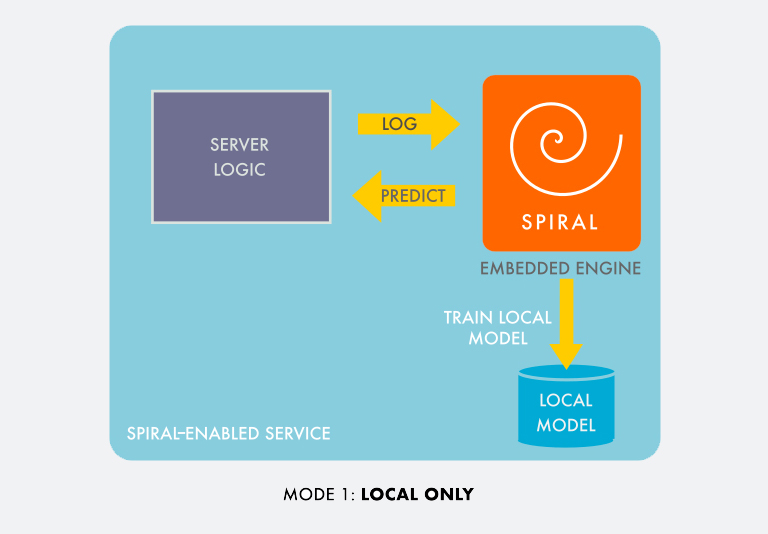
The library can operate in a fully embedded mode, or it can send feedback and statistics to the Spiral back-end service, which can visualize useful information for debugging, log data to long-term storage for later analysis, and perform the heavy lifting with training and selecting models that are too resource-intensive to train (but not too intensive to run) in the embedded mode.
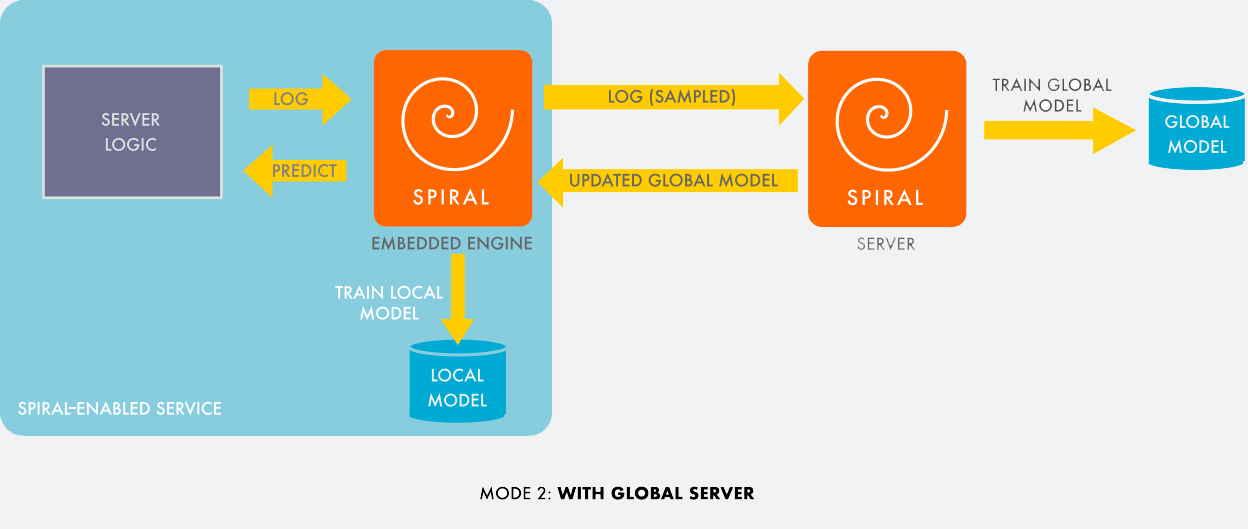
The data sent to the server is sampled with a counter-bias to avoid percolating class imbalance biases in the samples. For example, if over a period of time we receive 1,000 times more negative examples than positive ones, we need only log 1 in 1,000 negative examples to the server, while also indicating that it has a weight of 1,000. The server’s visibility into the global distribution of the data usually leads to a better model than any individual node’s local model. None of this requires any setup, aside from linking to a library and using the two functions above.
In Spiral, learning starts as soon as feedback comes in. Prediction quality improves progressively as more feedback is generated. In most services, feedback is available within seconds to minutes, so the development cycle is very short. Domain experts can add a new feature and see within minutes whether it is helping to improve the quality of predictions.
Unlike hard-coded heuristics, Spiral-based heuristics can adapt to changing conditions. In the case of a cache admission policy, for example, if certain types of items are requested less frequently, the feedback will retrain the classifier to reduce the likelihood of admitting such items without any need for human intervention.
Case study: Automating reactive caching heuristics
The first production use case for Spiral fit perfectly with Phil Karlton’s well-known quote, “There are only two hard things in computer science: cache invalidation and naming things.” (We already had an apt name for our project, so we did in fact tackle cache invalidation right away with Spiral.)
At Facebook, we rolled out a reactive cache that allows Spiral’s “users” (our other internal systems) to subscribe to query results. From the user’s perspective, this system provides the result of the query and a subscription to that result. Whenever an external event affects the query, it automatically sends the updated result to the client. This relieves the client of the burden of polling, and reduces load on the web front-end service that computes query results.
When a user submits a query, the reactive cache first sends the query to the web front-end, and then creates a subscription, and caches and returns the result. Along with the original result, the cache receives a list of objects and associations that were touched while computing the result. It then begins monitoring a stream of database updates to any objects or associations the query accessed. Whenever it sees an update that may affect one of the active subscriptions, the reactive cache reexecutes the query and compares the result with its cache. If the result did in fact change, it sends the new result to the client and updates its own cache.
One problem facing this system is that there is an enormous volume of database updates, but only a tiny fraction of them affect the output the query. If a query is interested in “Which of my friends liked this post?” it is unnecessary to get continuous updates on, for example, when the post was most recently viewed.
The problem is analogous to spam filtering: Given a message, should a system classify it as spam (does not affect query result) or ham (does affect query result)? The first solution was to manually create static blocklists. This was possible because the reactive cache engineering team recognized that over 99 percent of the load came from a very small set of queries. For low-volume queries, they simply assumed all updates were ham and reexecuted the query for every update to an object referenced by the query. For the small set of high-volume queries, they created blocklists by painstakingly observing the query execution to determine which fields in each object actually affected the output of the query. This process typically took a few weeks of an engineer’s time for each blocklist. To complicate things further, the set of high-volume queries was constantly changing, so blocklists quickly became outdated. Whenever a service using the cache changed the query it was executing, the system would have to change the spam-filtering policy, which required even more engineering work.
A Better Solution: Spiral spam filtering
After reexecuting a query, it is easy to determine whether the observed updates were spam or ham by simply comparing the new query result with the old query result. This mechanism was used to provide feedback to Spiral, allowing it to create a classifier for updates.
To ensure unbiased sampling, the reactive cache maintains and only provides feedback from a small subset of subscriptions. The cache does not filter updates to these subscriptions; the query is reexecuted whenever a relevant object or association is modified. It compares the new query output with the cached version and then uses that to provide feedback to Spiral — for example, telling it that updating “last viewed at” does not affect “like count.”
Spiral collects this feedback from all reactive cache servers and uses it to train a classifier for every distinct query type. These classifiers are periodically pushed to the cache servers. Creating filters for new queries or updating filters to respond to changing behavior in the web tier no longer requires any manual intervention from the engineering team. As feedback for new queries arrives, Spiral automatically creates a new classifier for those filters.
Faster deployment and more opportunities for Spiral
With a Spiral-based cache invalidation mechanism, the time required to support a new query in the reactive cache came down from weeks to minutes. Before Spiral, reactive cache engineers had to inspect each new query’s side effects by running experiments and collecting data manually. With Spiral, however, most use cases (mapping to a query) are learned by the local model automatically within minutes, so the local inference is available immediately. The server is able to train a model using data from multiple servers in 10 to 20 minutes for most use cases. Once published to all of the individual servers, this higher-quality model is available for improved fidelity inference. When a query is altered, the servers are able to adapt to the change and relearn the new materiality patterns once they receive the updated queries.
We are continuing to work on automating backend services and applying machine learning for a better operational experience. Spiral’s potential future applications include continuous parameter optimization using Bayesian optimization, model-based control, and online reinforcement learning techniques targeting high-QPS real-time services as well as offline (batch) systems. We’ll continue to share our work and results in future posts.
In an effort to be more inclusive in our language, we have edited this post to replace blacklist with blocklist.











