
Two years ago, Facebook open-sourced Zstandard v1.0, a landmark data compression solution that offers best-in-kind performance. Since then, we’ve released a variety of enhancements and advanced capabilities. While some of the improvements, such as faster decompression speed and stronger compression ratios, are included with each upgrade, others need to be explicitly requested. This post will walk through these new features and how they’ve delivered a second round of benefits at Facebook.
The initial promise of Zstandard (zstd) was that it would allow users to replace their existing data compression implementation (e.g., zlib) for one with significant improvements on all metrics (compression speed, compression ratio, and decompression speed). Once it delivered on that promise, we quickly began to replace zlib with zstd. This was no small undertaking, and there is a long tail of projects to get to. However, through creative refactoring of accretion points, notably folly, we have converted a significant portion in record time (as reported by our internal monitoring system). The benefits we’ve found typically range from a 30 percent better ratio to 3x better speed. Each service chooses to optimize for gains on one of these axes, depending on its priorities.
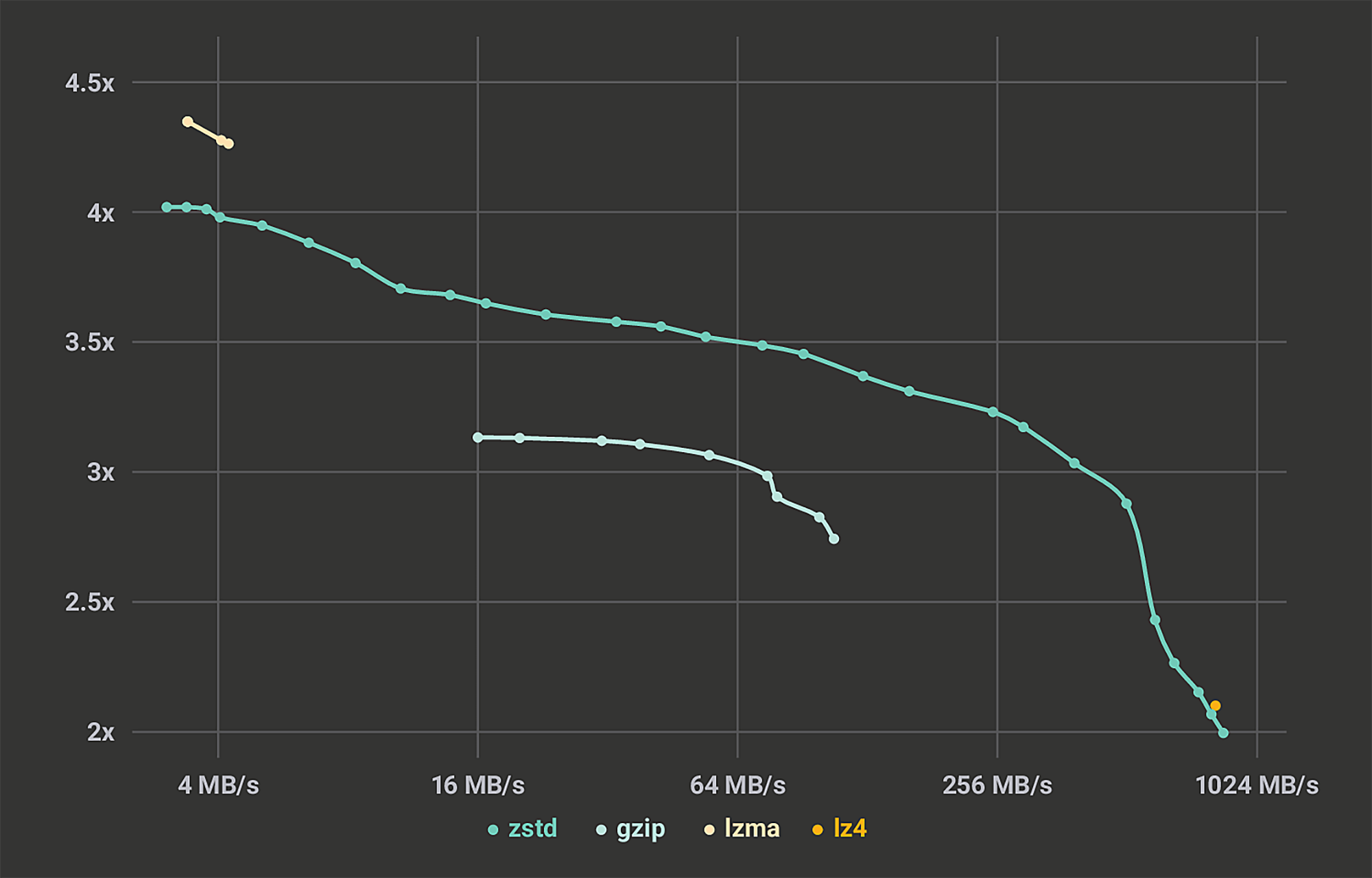
In addition to replacing zlib, zstd has taken over many of the jobs that traditionally relied on fast compression alternatives. Save the fastest ones, which are still served by LZ4, zstd provides a much better ratio (+50 percent). It has also begun to replace the strong compression scenarios previously served by XZ, for the benefit of >10x faster decompression speed. With all these use cases combined, zstd now processes a significant amount of data every day at Facebook.
Replacing existing codecs is a good place to start, but zstd can do so much more. In this post, we walk through the benefits we found and some of the lessons we learned as we implemented these advanced features. Since the benefits depend on the target use case, we’ll focus on several representative cases, moving from the largest packages to the smallest records.
Use case 1: Very large payloads
Facebook regularly backs up its engineers’ development servers, so developers can restore any lost work if a machine goes down. Backups can be hundreds of gigabytes in size, and unlike most compression use cases, the data is almost never decompressed. That is, backups are write-once and read-never. The priorities for this case are compression efficiency and compressed size — and we can allow increased resources for decompression.
Similarly, Facebook’s package distribution system, fbpkg, is responsible for distributing large files to the fleet. With such large files, fbpkg prioritizes compression efficiency and speed. However, it can’t sacrifice any decompression speed, since it is write-once and read-many.
MultiThreaded Compression
We added multithreading (-T#) to ensure that compression isn’t a bottleneck for the backup process and that people don’t have to wait for it to finish when building packages. Multithreaded compression can nearly linearly speed up compression per core, with almost no loss of ratio. Development server backups use two cores to match the speed of the rest of the pipeline (-T2), and fbpkg uses all the available cores (-T0).
Long Range Mode
The next feature tailored to large data is long range mode (--long). Zstd already supported large window sizes (up to 512 MB) but didn’t have an efficient algorithm to search that space quickly. We increased the maximum window size to 2 GB and added a special preprocessor to find matches in that large window at 100 MB/s. Long range mode works in tandem with the regular zstd compression levels.
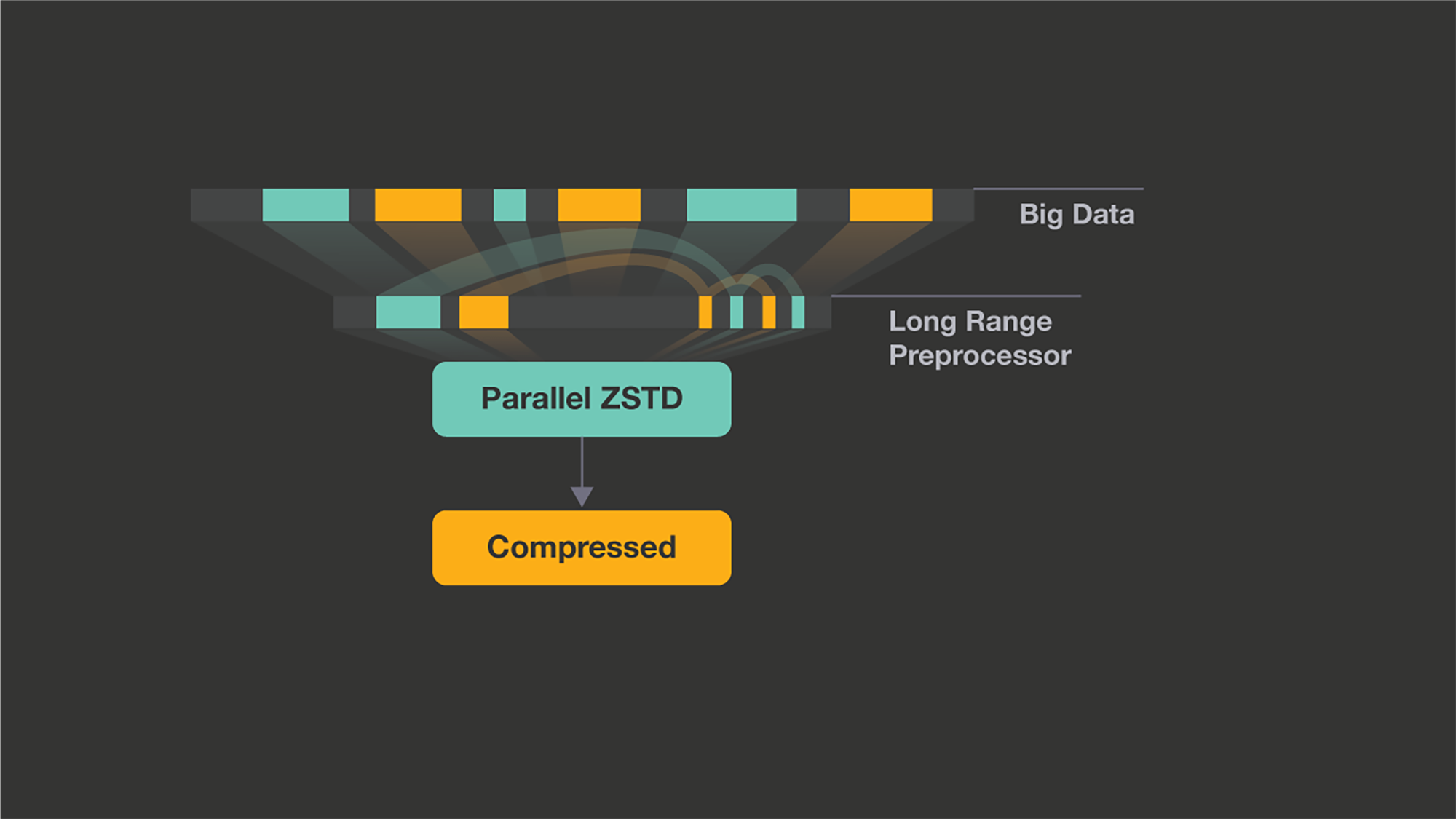
Long range mode is a serial preprocessor which finds large matches and passes the rest to a parallel zstd backend.
Development server backups use the full 2 GB window (--long=31) because it is fine to require decompressors to allocate 2 GB during server recovery. Adding long range mode reduced the full backup size by 16 percent and the diff backup size by 27 percent. Switching to long range mode also reduced the P90 backup time by 16 percent, while the median backup time remained approximately the same. Fbpkg uses only a 128 MB window size (--long) because we can’t allocate too much memory to decompression on production hosts. However, large packages became about 10 percent smaller, and in extreme cases the size was reduced 5x. You can learn more about multithreading and long range mode in the zstd-1.3.4 release notes.
Automatic Level Determination
The last feature introduced for large data streams is automatic level determination (--adapt). Adaptive mode measures the speed of the input and output files, or pipes, and adjusts the compression level to match the bottleneck. This mode can be combined with multithreading and long range mode and finely controlled through lower and upper bounds. Combining all three is perfect for server backups because the algorithm can opportunistically convert wait time due to network congestion into improved compression ratio. In initial experiments, we measured an improvement of approximately 10 percent in compression ratio for equivalent or better transmission time.
Use case 2: Warehouse
One component of Facebook’s infrastructure is the data warehouse: Most long-term data is stored there, and it represents a significant part of our total storage footprint. The warehouse is based on Hadoop and is mostly accessed by batch operations (i.e., most accesses are sequential), with occasional random access. To serve this pattern of use and to achieve good compression, the data is stored in a columnar store (e.g., in ORC files), in which each column in a table is grouped together into its own file. Inside each file, data is subdivided again into medium-size blocks (most commonly 256 KB). Then each block is compressed independently.
We started by replacing zlib with zstd. Just this replacement improved compression ratio and speed by double-digit percentages. When you consider the scale of the warehouse, this is already a huge improvement. But using zstd like zlib is just a first step. Armed with new capabilities, we were able to reassess the validity of some legacy choices.
Increased Block Size
First, why is the block size set to 256 KB? In the context of zlib, which can only use 32 KB of history, it made sense. Because 256 KB is eight times larger than the zlib window, increasing the block size further generated very limited gains and affected parallel processing.
In contrast, zstd can effectively make use of megabytes of history (and even more when explicitly requested). With zstd, increasing the block size beyond 256 KB generates significant incremental compression benefits. However, other forces prevent blocks from scaling to arbitrary sizes. Large blocks consume more memory during handling. And random access reads, while not the bulk of the workload, require decompressing the whole block to access an individual element. So it’s useful to keep the block size below a certain threshold. Nevertheless, this is an easily accessible configuration parameter and can now be tuned as needed to produce additional benefits.
Fewer Data Transformations
Another aspect of the pipeline is that it features data transformations that were designed to “help” zlib compression. This is another consequence of the same problem. With history limited to 32 KB, there’s only so much redundancy zlib can capture. So it can be useful to capture long-distance redundancy separately and “feed” the compressor with predigested data. It works well. But these transformations generate their own CPU and memory requirements in both directions (compression and decompression), and when pushed far enough, they contribute significantly to the computational cost.
Once again, zstd’s ability to analyze larger history makes some of these transformations less necessary, so it is possible to reconsider their usage. It’s not an outright elimination, but a neat reduction in the number of transformation stages and dependent use cases brings corresponding savings in CPU capacity, memory, and latency.
These examples illustrate secondary order gains. Beyond better compression as an immediate benefit, it pays to reconsider the pipeline in order to extract more benefits from the new compression engine.
Use case 3: Compressed filesystems
Faster deployments with SquashFS
SquashFS is a popular read-only compressed filesystem. A SquashFS file is like a mountable tarball that allows random access by compressing the data in blocks and caching decompressed data in the page cache. Facebook uses SquashFS to deliver HHVM binaries and bytecode, and to deliver Python scripts as XARs, which are simply self-extracting SquashFS filesystems. Decompression speed and compressed size are important to these use cases.
Initially, we used gzip with a 128 KB block size for these use cases. However, the read speed was slow, so we added zstd support to SquashFS and switched over. Zstd offers much faster decompression and stronger compression. It also makes better use of larger blocks, so we use 256 KB blocks as a middle ground between miss latency and compressed size. When we switched the HHVM binary and bytecode to zstd, we saw 2x faster reads, and the packages were 15 percent smaller.
Tighter storage with Btrfs
Btrfs is a modern copy-on-write filesystem that, among other things, offers transparent compression. Facebook has invested heavily in Btrfs but until recently hasn’t made use of the transparent compression. We added zstd support to Btrfs in an effort to change that. Facebook uses Btrfs on our development servers, which run in virtual machines, with multiple VMs on one server. Storage space can get tight because multiple developers share a single SSD, and engineers can run out of space.
As soon as we enabled zstd compression, developers perceived 3x more storage, on average, without a noticeable drop in performance. We are still in the early days of transparent zstd compression in Btrfs, but we hope to see the usage grow over time. One promising use case is to enable zstd compression for our services running on SSDs, to improve the flash burn rate. We are currently upstreaming support for selecting zstd compression levels and for GRUB.
Use case 4: Databases
Hybrid compression
Facebook uses a number of databases in production, but many of them are actually powered by the same underlying storage engine, RocksDB. For example, MyRocks is our project to run MySQL on RocksDB, Rocksandra is Cassandra on RocksDB, and ZippyDB is an internal database built on top of RocksDB.
Database workloads feature a fair amount of random access scenarios, retrieving a number of small fields scattered all across the database. Any design suffers from a tension between storage efficiency and random access latency. In order to extract some benefits from compression, fields of the same type are grouped into blocks, large enough to compress meaningfully but small enough to extract single elements with reasonable latency.
For efficiency reasons, RocksDB features a leveled architecture, where data is positioned based on how frequently it is accessed. RocksDB has the flexibility to choose different compression algorithms between levels. In MyRocks deployments (UDB — the biggest database tier at Facebook, and Facebook Messenger), we decided to use zstd in the bottommost level (where most data files are placed) and to use LZ4 for other levels. LZ4 is faster for compression, which helps to keep up with write ingestion. Zstd in the bottommost level is able to save even more space than zlib, while preserving excellent read speeds. This hybrid compression setting has been a great success and inspired our Rocksandra environments. This migration in itself had a pretty big impact, considering the size of these systems. But we didn’t stop there.
There are many client systems plugged into these databases, featuring vastly different requirements. When compression was performed by fast but weak engines, some systems would precompress their data before storage. With zstd now providing more efficient compression, this extra step becomes superfluous. But benefits are even larger: Where the client previously had to compress each field separately, the storage engine can now compress multiple fields together within blocks, yielding even better compression ratios and faster processing speed. This is one case in which removing a compression stage results in an overall better compression ratio on top of better latency.
Dictionary Compression
With databases under increased pressure to deliver more requests, the original choice of 16 KB blocks comes into question. This time, the opportunity is to reduce block sizes to offer faster latency when accessing a single element in the block. But reducing the block size negatively affects compression ratio, leading to unacceptable storage costs. With zstd, we have a way to mitigate that effect, called dictionary compression.

Dictionaries are generated from samples of the use case’s data and capture common patterns in the data.
A dictionary makes it possible for the compressor to start from a useful state instead of from an empty one, making compression immediately effective, even when presented with just a few hundred bytes. The dictionary is generated by analyzing sample data, presuming that the rest of the data to compress will be similar. The zstd library offers dictionary generation capabilities that can be integrated directly into the database engine.
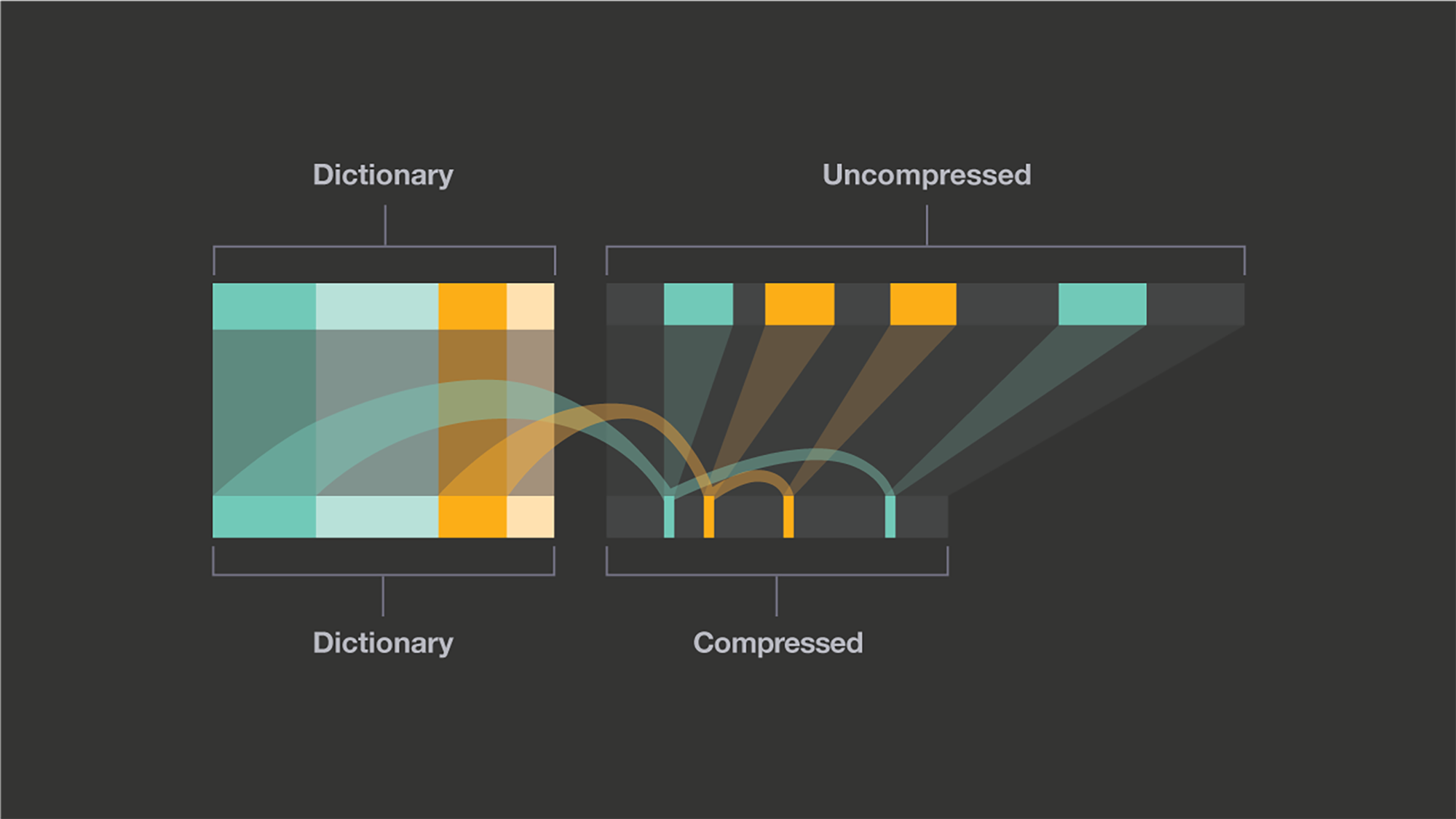
Once the patterns have been captured, the dictionary assumes future data will be similar and begins compression immediately.
The end result was satisfying: Using dictionaries more than offset the compression reduction introduced by smaller blocks, meaning the database can now serve more queries and compact data even further. Of course, this result wasn’t as straightforward as swapping a compression engine. The database must now generate and store dictionaries, zstd must be able to generate these dictionaries within tight timeframes, the API must be able to juggle thousands of states simultaneously in memory. But that’s one situation where having both storage engine and compression working together can lead to tighter integration and deliver some exciting novel solutions.
Use case 5: Managed Compression
RocksDB, and the databases that use it, are such gigantic use cases that almost any amount of effort is justified if it produces efficiency benefits. There are many other contexts and applications in which dictionary-based compression would provide large wins.
Dictionary compression has a successful implementation story within Facebook’s massive messaging infrastructure. It started when trying to subdue a particular service that was blowing past its write-rate limit. The engineer decided dictionary-based compression was worth a try. It quickly became clear that the new technique would greatly cut the service’s storage appetite.
However, dictionaries introduce their own complexities. Compression is commonly thought of as a deterministic transformation that is implemented by two stateless, pure functions: compress() and decompress(). Many compression libraries reinforce this idea, by providing that sort of stateless API. But this is a convenient simplification. In reality, compression and decompression are intimately concerned with maintaining an internal state throughout the operation, which can be very long, and can span many calls to the library when streaming.
In contrast with the idealized view of compression, dictionaries are a bundle of explicit state. As such, they present both promises and concerns. They promise better compression by allowing the compressor to hit the ground running, but they require grappling with statefulness in all its complexity. Dictionaries must be generated by running an algorithm over samples of production data (which must be gathered). They have to be stored. They have to be distributed everywhere the application is running. The same dictionary that was used at compression must be used when that piece of data is decompressed. If the nature of the data being compressed changes, the dictionary must be updated, inviting push safety and versioning concerns into the mix.
Fortunately, managing state is not a new problem. Facebook has existing, well-understood infrastructure for logging things, for storing data, for running offline cron-style jobs, for configuration distribution, and so on. These are basic, necessary building blocks for engineering organizations at scale. And the zstd binary itself includes a dictionary trainer (zstd --train). Building a pipeline for handling compression dictionaries can therefore be reduced to being a matter of gluing these building blocks together in relatively straightforward ways.
So, a first solution was created along these lines, “duct-taped” systems together, and pushed an integration to production. It might not have been pretty, but it worked nicely. Dictionary-based compression halved the storage footprint and quartered the write rate! The service was saved, and capacity liaison smiled (probably).
It wasn’t long before we realized that this method could be applied to other services in the stack. New integrations were started, and … didn’t get very far.
Managed Compression
Re-creating a similar solution for each service was simply wasteful, and the engineer quickly realized all those operations (capturing samples, training and storing dictionaries, configuration, etc.) could be automated. Instead of doing the same work poorly multiple times, it was preferable to do it right once, in a way that could be shared between all services, and in a place where experience and quality could be concentrated.
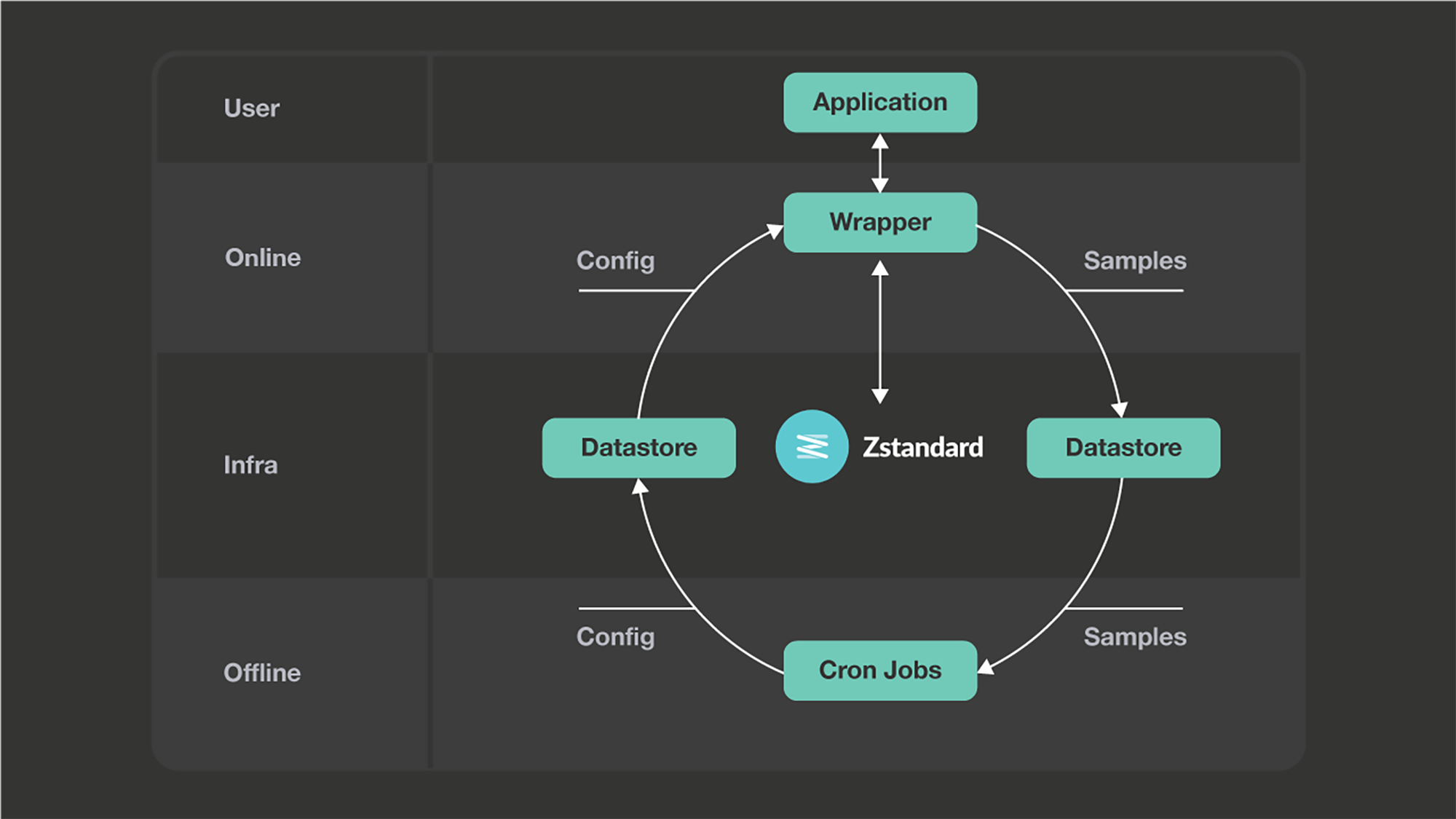
The solution, called managed compression, is split into halves: an online half and an offline half. It has been deployed at Facebook and relies on several core services. The online part is a library that users integrate into their applications. First and foremost, it is a wrapper around the zstd library, which is what actually compresses and decompresses. In addition, it does two things: It loads configuration information, including dictionaries, from our configuration distribution system, and presents those things to zstd, and it logs samples (and errors and performance metrics) to our logging pipeline.
The offline component is a set of scripts that run on our cron infrastructure. These look at the exported metrics and samples from the library in production and tune the config, primarily by training new candidate dictionaries and comparing them with existing dictionaries in production. If a candidate is found to be better than its existing counterpart, it’s shipped to production, and the library picks it up and uses it for new compressions.
A design goal that quickly emerged is that the solution must be simple to use. Managed compression internally keeps lots of states but exposes exactly the same “stateless” and “pure” signature to the user as a usual compression library. Hence, getting started using managed compression needs no configuration nor registration. Just create a codec object, select a category, link it in, and go. More capabilities and direct controls are available, typically on the monitoring side, but they are in no way essential for the service to run: New users can reach them later, as an optimization or refinement stage.
Managed compression quickly became popular. After converting messaging infrastructure, services across the company began to use it, and its maintenance required more and more time from its creator. It became his full-time job.
One important use case for managed compression is compressing values in caches. Traditional compression is not very effective in caches, since each value must be compressed individually. Managed compression exploits knowledge of the structure of the key (when available) to intelligently group values into self-similar categories. It then trains and ships dictionaries for the highest-volume categories. The gains vary by use case but can be significant. Our caches can store up to 40 percent more data using the same hardware.
Managed compression is now used by hundreds of use cases across Facebook’s infrastructure. Over and over, we’ve seen it deliver consistent, significant compression ratio improvements (on average, 50 percent better than the regular compression methods it replaced).
Managed compression has also expanded beyond managing dictionaries. Sampling use cases’ production data is a powerful tool: It allows us to programmatically analyze each use case and automatically deploy optimizations that previously would have taken laborious manual experimentation. For example, managed compression runs paramgrill (an experimental tool available in the zstd repository) to experiment and select advanced compression parameters that perform better than existing ones.
As managed compression scaled and its users began to include important systems, reliability became a concern. So it was hardened against various failure modes. Overall, reliability crept upward from six nines, to seven nines, and eventually to better than eight nines of reliability.
These results are achieved thanks to the underlying infrastructure, as well as the flexible and fault-tolerant nature of the solution. We can completely lose the offline side of managed compression, without impacting any live service. There are automated checks at every stage of a new deployment. The dependency chains (services that managed compression rely upon) can be adapted, per service, in order to match the existing dependency chain of target service, which is important for the reliability of core services. For the online portion, failures can be copped with automated backup modes: escape to an older present dictionary, or even don’t use a dictionary at all.
As the long tail was analyzed, it became clear that managed compression could have a non-zero failure rate and still not meaningfully impact its users’ overall reliability. Addressing that last 0.000001 percent of failures can feel overwhelming, given that it mostly consists of black swan events. But that’s where quality is, and the team is committed to the reliability of this infrastructure, by limiting the dependency chain and gracefully degrading when dependencies fail.
What’s next?
Combined, these features make Zstandard a very powerful and flexible compressor engine. Zstd continues to provide best-in-kind performance in many conventional situations, and has accumulated a number of features that allow it to succeed in real-world scenarios that traditionally have been difficult for compressors.
In many of these situations, the conventional approach has been to structure the surrounding system in ways that allow the compressor to achieve good performance, even when that means handling data in otherwise inconvenient and unnatural ways. Taking advantage of the advanced features described in this post requires experimentation and care, but the benefits realized in doing so are not limited to better performance. We have found that they can make the systems that use them simpler overall because they can now handle data in more natural ways.
Taking a broader view, we believe compression systems such as managed compression are the future of data compression at scale. While compression tools have historically been confined to operating statelessly, the environments in which they are used are rarely stateless themselves. In those situations, stateful compression can dramatically improve system efficiency in ways that neither meaningfully increase the system’s dependency footprint nor decrease its overall reliability.
We hope this post has inspired some ideas about how to better use compression in many applications. The advanced features we’ve described are all accessible now in the zstd command-line tool.
Advanced features are also available for integration into applications, through the library. For now, they have been exposed in a section of the API labeled “experimental.” Starting with v1.3.8, a large portion of the advanced API will reach the staging area, which is the last step before becoming stable.
We invite programmers interested in these advanced capabilities to test and play with this new API proposal, as it is also the last chance to review it and provide feedback. We plan for the advanced API to become stable by v1.4.0 . Your feedback and experiences are welcome!











