
It’s no secret that Facebook operates at a huge scale–something we can do only with an infrastructure organization truly dedicated to efficiency and automation.
We have built a flexible automation system, called MySQL Pool Scanner, that makes life much easier for our team. It’s usually referred to as “MPS,” because hey, who doesn’t like a three-letter acronym? Efficiency!
MPS automatically detects a wide variety of problems on hosts and performs actions such as secondary promotions and MySQL instance replacements as necessary. However, the system can only continue to do its job if there are enough spare MySQL server instances available. This is where our automated system for database provisioning — which we call “Windex” — comes in.
Windex was originally developed to wipe data from hosts coming out of production, reinstall everything from the OS through to MySQL, and then configure them so they could be placed back into the spares pool all shiny and new.
Now, Windex has expanded its role to cover all provisioning of MySQL DB hosts, whether they are freshly racked and set up by our site operations team or taken out of production for an offline repair like RAM replacement.
How it works
To get an idea of how Windex works and what it does, let’s first look at the typical flow a system coming out of production for repair would follow:
-
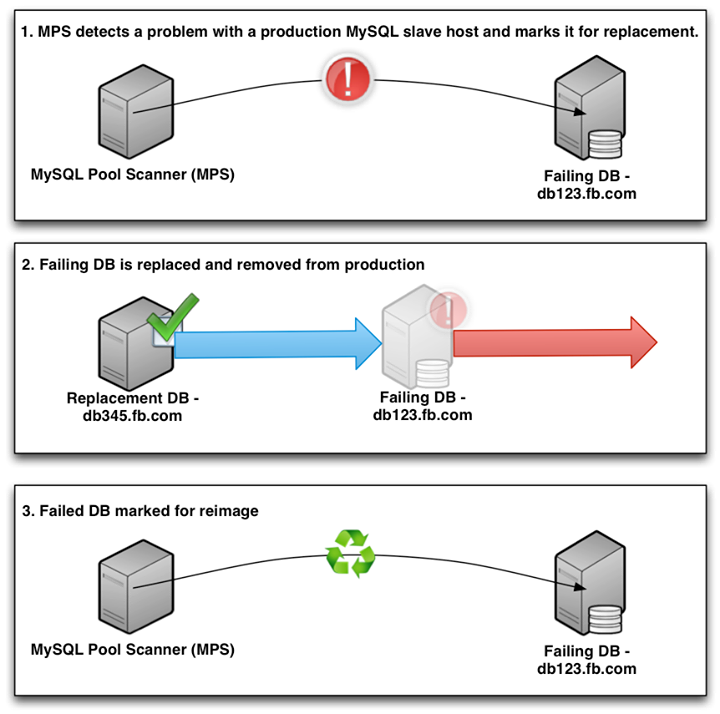
- MPS detects a problem with a production MySQL secondary host.
- MPS replaces the problematic secondary with a host from the spares pool.
- MPS puts the problem host into “re-image” status.
-
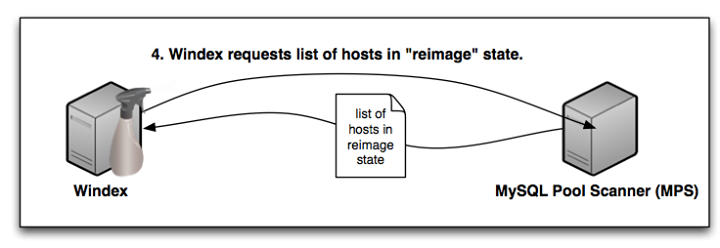
- Windex periodically polls MPS for hosts in “re-image”status and finds a new host to do work on.
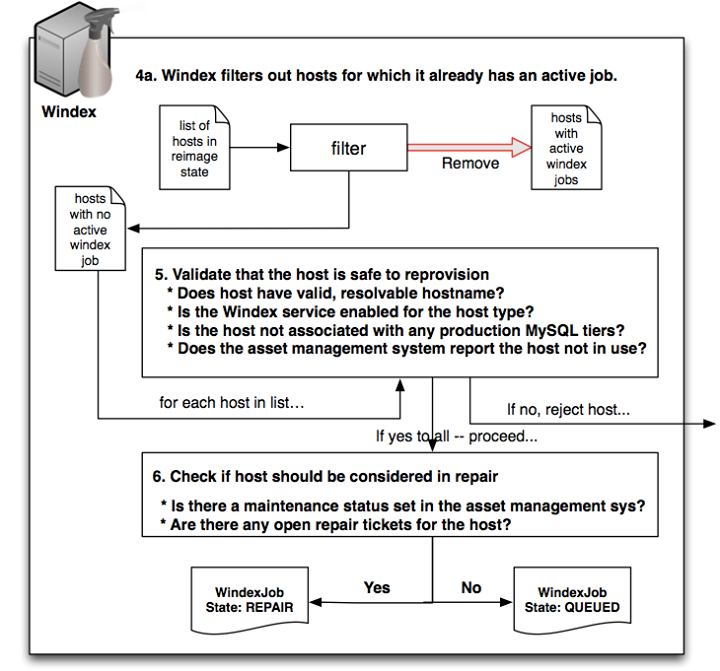
- Windex performs a series of checks to verify that the system is safe to reprovision. Examples include:
- -Is the host a valid, resolvable host name?
- -Is the Windex re-imaging service enabled for this type of host?
- -Is the host not associated with any production MySQL service tiers?
- -Is the status for the host no longer set to “in use” in the asset management system?
- If the host passes the validation above, Windex will check to see if the job should be in the “repair” state by querying the asset management and repair system,looking for any maintenance status, and opening repair tickets. If the host has maintenance status, a job is created in “repair” state. Otherwise, it’s just put into “queued” status.
Windex jobs in repair state are periodically rechecked for repair status. Once the repair status is cleared, the job will be put into the “queued” state, ready to be worked on.
-
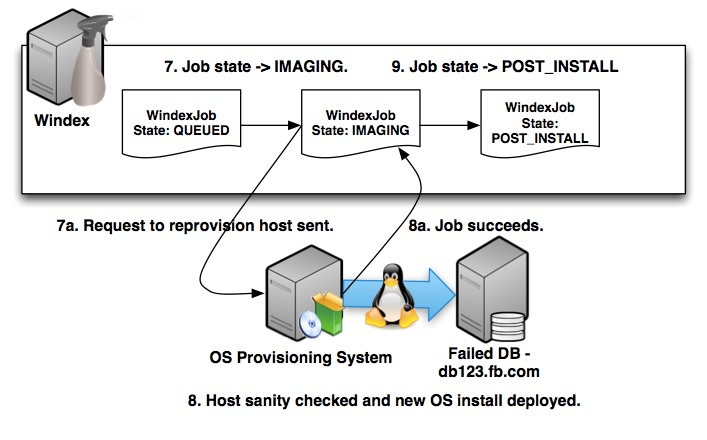
- The “queued” host is moved into the “imaging” state and a request is sent to our automated provisioning system to re-image the host with a fresh install of the base OS and some core packages.
- The automated provisioning system performs a variety of sanity checks on the system to make sure it’s viable for use. If any of those fail, a repair ticket is automatically opened for the host and the provision job is failed. If the machine passes the checks, the provision job is run.
- Windex sees the provisioning system job complete successfully and moves the job into the “post install” state.
-
- During the post install stage, a script is run that ensures the correct MySQL packages are installed, configured, and initialized. Upon success the job is moved to the “check install” state.
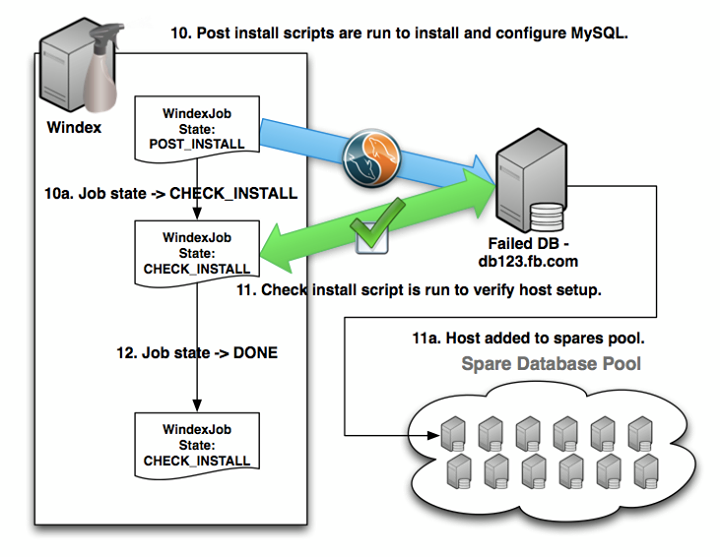
- During the check install stage, another script is used that runs the host through a full suite of checks to ensure that it is ready to be put into the production environment. Upon success, it’s added to the spares pool, ready for MPS to use for replacing other systems.
- The Windex job is moved to “done” status.
To make Windex work on new hosts, we simply create them in a “re-image” state in the MPS database. MPS picks up these new hosts at step 4 in the flow outlined above, when it scans the MPS system for hosts in the re-image state.
The above example is a fairly simplified, ideal-world scenario. But Windex also has some rudimentary retry and failure pattern detection logic built in to help in less-than-ideal situations.
Retry and failure pattern detection
The retry logic works like it sounds — if something like the provision job or post-install scripts fail, Windex will retry that step, up to N times, where N is some configurable number. For example, if an attempt to provision the host fails five times, then Windex will simply mark the job as failed. Similarly, if the post-install scripts fail after 10 attempts, the job will also be marked as failed.
In cases where the retries are exhausted as described above, and Windex fails the job, a new job will be created automatically by Windex, provided that the host is still in the re-image state and all the validation checks pass. This creates the possibility of an infinite loop of Windex creating a job, attempting to process the job, failing to do so, and then marking the job as failed.
The failure pattern logic in Windex catches this by keeping track of consecutive failures for a host. Each time a job fails, Windex stores a failure entry for the host, referring back to the failed job. If a host experiences a certain number of consecutive failures, Windex will put the failing job into a “needs review” state instead of “failed.” This state is considered an active state by Windex, which will prevent it from trying to create any more new jobs for the host.
An engineer will periodically review hosts in the “needs review” state to address whatever was causing the failure to provision. Once that is handled, the “needs review” state is cleared, along with the failure count, and Windex will happily begin processing the host all over again.
Aside from preventing an infinite loop of failed provision jobs, having a workflow like this has really helped us tighten up our automation. Previously such repeat offenders may have just been sitting in a rack somewhere doing nothing, but now we are able to identify and fix the root causes and get these hosts back to work.
Preventing damage
All of the above makes for a very helpful system, but what about the potential for chaos?
The verification logic from step 5 in the example above helps us ensure that our databases and other systems are safe for Windex to work on. That verification is applied not only as a gating factor to creating a new job in Windex, but also immediately before Windex does anything at each step in the different stages of provisioning. This is the most important thing to get right for any automation systems we have managing our MySQL servers.
Take the following example:
- Let’s say we upgraded the BIOS for all the spare database hosts in one data center, but forgot to update the list of versions that MPS should consider valid. As a result, MPS would detect these hosts as having an invalid BIOS version and put them into the”re-image” state so that Windex would reprovision them.
- The DBA on call would receive an alert that there are no longer any spares available in the given data center. Upon investigation, the DBA would find the cause of the issue and update the valid BIOS versions list in MPS so it would no longer consider the new BIOS version bad.
- Meanwhile, Windex would detect all these new hosts in the “re-image” state and create “queued” Windex jobs for them to be re-imaged.
- The DBA would then conclude that since all these hosts were erroneously sent for re-image and the data center had no spares available, he or she would just put them back into the spares pool, since there was really nothing wrong with them. He or she would then set the state of the instances to “spare.”
- MPS would then pick up some of these spares and use them to replace some other hosts in production that were experiencing legitimate failures.
At this point you have a recipe for disaster — production hosts queued for re-imaging. Thankfully, since Windex will validate the host again before it attempts to re-image, it will detect that the MPS state for the hosts are no longer “re-image” and move them to the “rejected” state without causing any damage whatsoever.
This is one example of why frequent validation is so important. It may sound like something that could only hit once in a while, but you would be surprised how often we come across situations where it helps.
Windex has only been a part of our automation infrastructure for a short time, but it has already performed thousands of successful jobs across our fleet of database hosts and has greatly increased the efficiency of the team.
Lachlan is a MySQL database engineer on the MySQL operations team.
In an effort to be more inclusive in our language, we have edited this post to replace the terms “master” and “slave” with “primary” and “secondary.”











