
A log is the simplest way to record an ordered sequence of immutable records and store them reliably. Build a data intensive distributed service and chances are you will need a log or two somewhere. At Facebook, we build a lot of big distributed services that store and process data. Want to connect two stages of a data processing pipeline without having to worry about flow control or data loss? Have one stage write into a log and the other read from it. Maintaining an index on a large distributed database? Have the indexing service read the update log to apply all the changes in the right order. Got a sequence of work items to be executed in a specific order a week later? Write them into a log, have the consumer lag a week. Dream of distributed transactions? A log with enough capacity to order all your writes makes them possible. Durability concerns? Use a write-ahead log.
At Facebook’s scale, all of that is much easier said than done. The log abstraction carries with it two important promises that are difficult to fulfill at scale: highly available and durable record storage, and a repeatable total order on those records. LogDevice attempts to deliver on those two promises, so dear to the heart of a distributed system designer, at an essentially unlimited scale. It is a distributed data store designed specifically for logs.
The log can be viewed as a record-oriented, append-only, and trimmable file. Let’s look at what this means in more detail:
- Record-oriented means that data is written into the log in indivisible records, rather than individual bytes. More importantly, a record is the smallest unit of addressing: A reader always starts reading from a particular record (or from the next record to be appended to the log) and receives data one or more records at a time. Still more importantly, record numbering is not guaranteed to be continuous. There may be gaps in the numbering sequence, and the writer does not know in advance what log sequence number (LSN) its record will be assigned upon a successful write. Because LogDevice is not bound by the continuous byte numbering requirement it can offer better write availability in the presence of failures.
- Logs are naturally append-only. No support for modifying existing records is necessary or provided.
- Logs are expected to live for a relatively long time — days, months, or even years — before they are deleted. The primary space reclamation mechanism for logs is trimming, or dropping the oldest records according to either a time- or space-based retention policy.
The relaxed data model of LogDevice allowed us to reach more optimal points in the trade-off space of availability, durability, and performance than what would be possible for a distributed file system strictly adhering to the POSIX semantics, or for a log store built on top of such a file system.
Workload and performance requirements
Facebook has a variety of logging workloads with highly variable performance, availability, and latency requirements. We designed LogDevice to be tunable for all those conflicting objectives, rather than a one-size-fits-all solution.
What we found common to most of our logging applications is the requirement of high write availability. The loggers just don’t have anywhere to park their data, even for a few minutes. LogDevice must be there for them, available. The durability requirement is also universal. As in any file system no one wants to hear that their data was lost after they received an acknowledgement of a successful append to a log. Hardware failures are no excuse. Finally, we discovered that while most of the time log records are read just a few times, and very soon after they are appended to a log, our clients occasionally perform massive backfills. A backfill is a challenging access pattern where a client of LogDevice starts at least one reader per log for records that are hours or even days old. Those readers then proceed to read everything in every log from that point on. The backfills are usually precipitated by failures in the downstream systems that consume log records containing state updates or events. A backfill allows the downstream system to rebuild the state that was lost.
It’s also important to be able to cope with spikes in the write load on individual logs. A LogDevice cluster typically hosts thousands to hundreds of thousands of logs. We found that on some of our clusters the write rate on a few logs may see a 10x or higher spike over the steady state, while the write rate on the majority of the logs handled by that LogDevice cluster does not change. LogDevice separates record sequencing from record storage, and uses non-deterministic placement of records to improve write availability and better tolerate temporary load imbalances caused by such spikes.
Consistency guarantees
The consistency guarantees provided by a LogDevice log are what one would expect from a file, albeit a record-oriented one. Multiple writers can append records to the same log concurrently. All those records will be delivered to all readers of the log in the same order, namely the order of their LSNs, with repeatable read consistency. If a record was delivered to one reader, it will also be delivered to all readers encountering that LSN, barring unlikely catastrophic failures that result in the loss of all copies of the record. LogDevice provides built-in data loss detection and reporting. Should data loss occur, the LSNs of all records that were lost will be reported to every reader that attempts to read the affected log and range of LSNs.
No ordering guarantees are provided for records of different logs. The LSNs of records from different logs are not comparable.
Design and implementation
Non-deterministic record placement
It’s good to have options. Having a large number of placement options for record copies improves write availability in a distributed storage cluster. Similar to many other distributed storage systems, LogDevice achieves durability by storing several identical copies of each record (typically two or three) on different machines. With many placement options for those copies you can complete writes even if a lot of storage nodes in your cluster are down or slow, as long as the part of the cluster that is up can still handle the load. You can also accommodate spikes in the write rate on a single log by spreading the writes over all the nodes available. Conversely, if a particular log or record is restricted to just a few specific nodes, the maximum throughput of a single log will be limited by the capacity of those nodes, and the failure of just a few nodes may cause all writes on some logs to fail.
The principle of maximizing placement options for incoming data is employed by many successful distributed file systems. In Apache HDFS for instance a data block can be placed on any storage node in the cluster, subject to the cross-rack and space constraints enforced by the centralized metadata repository called the name node. In Red Hat Ceph data placement is controlled by a multi-valued hash function. The values produced by the hash function provide multiple placement options for an incoming data item. This eliminates the need for a name node but cannot quite reach the same level of placement flexibility.
LogDevice, with its focus on log storage, takes a different approach to record placement. It provides the level of placement flexibility equivalent to that offered by a name node without actually requiring a name node. Here is how this is accomplished. First, we decouple the ordering of records in a log from the actual storage of record copies. For each log in a LogDevice cluster LogDevice runs a sequencer object whose sole job is to issue monotonically increasing sequence numbers as records are appended to that log. The sequencer may run wherever it is convenient: on a storage node, or on a node reserved for sequencing and append execution that does no storage.
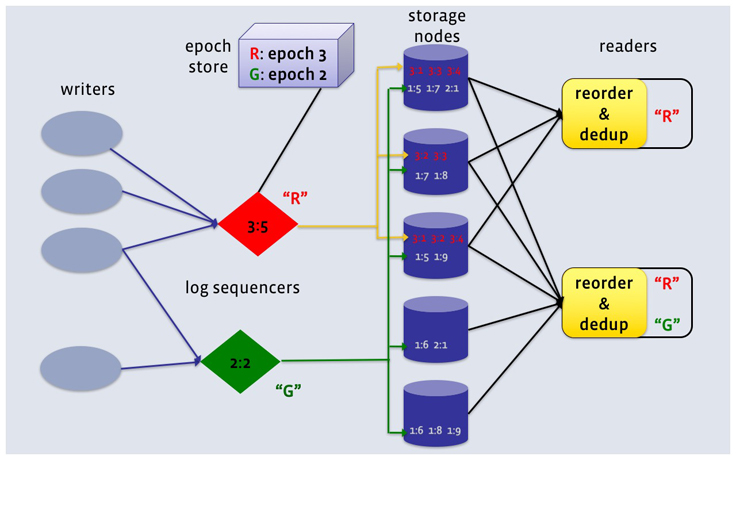
Once a record is stamped with a sequence number, the copies of that record may potentially be stored on any storage node in the cluster. Their placement will not affect the repeatable read property of the log as long as readers can efficiently find and retrieve the copies.
A client that wishes to read a particular log contacts all storage nodes that are permitted to store records of that log. That set, called the node set of the log is usually kept smaller than the total number of storage nodes in the cluster. The node set is a part of the log’s replication policy. It can be changed at any time, with an appropriate note in the log’s metadata history, which the readers consult in order to find the storage nodes to connect to. Node sets allow LogDevice clusters to scale independently from the number of readers. The nodes contacted by the client deliver record copies to it by pushing them into TCP connections as fast as they can. Naturally, the header of each record includes its sequence number. The LogDevice client library performs the reordering and occasional de-duplication of records necessary to ensure that the records are delivered to the reader application in the order of their LSNs.
While this placement and delivery scheme is great for write availability and handling spiky write workloads, it would not be very efficient for file workloads that often include many point reads. For log reading workloads, which are largely sequential, it is quite efficient. All storage nodes contacted by a reader will likely have some records to deliver. No IO and network resources are wasted. We ensure that only one copy of every record is read from disk and delivered over the network by including the copy set in the header of every record copy. A simple server-side filtering scheme based on copy sets coupled with a dense copy set index guarantees that in steady state only one node in the copy set would read and delivery a copy of the record to a particular reader.
Sequence numbers
As shown in Figure 1, the sequence numbers of records in LogDevice are not integers, but pairs of integers. The first component of the pair is called the epoch number, the second one is offset within epoch. The usual tuple comparison rules apply. The use of epochs in LSNs is another availability optimization. When a sequencer node crashes or otherwise becomes unavailable LogDevice must bring up replacement sequencer objects for all the affected logs. The LSNs that each new sequencer starts to issue must be strictly greater than the LSNs of all records already written for that log. Epochs allow LogDevice to guarantee this without actually looking at what has been stored. When a new sequencer comes up it receives a new epoch number from the metadata component called the epoch store. The epoch store acts as a repository of durable counters, one per log, that are seldom incremented and are guaranteed to never regress. Today we use Apache Zookeeper as the epoch store for LogDevice.
Many-to-many rebuilding
Drives fail. Power supplies fail. Rack switches fail. As these failures occur the number of available copies decreases for some or all records. When after several consecutive failures that number drops to zero we have data loss or at least the loss of read availability of some records. Both are bad outcomes that LogDevice tries to avoid as much as possible. Rebuilding creates more copies for records that have become under-replicated (have fewer than the target number of copies R) after one or more failures.
In order to be effective, rebuilding has to be fast. It must complete before the next failure takes out the last copy of some unlucky record. Similar to HDFS the rebuilding implemented by LogDevice is many-to-many. All storage nodes act as both donors and recipients of record copies. Marshaling resources of the entire cluster for rebuilding allows LogDevice to fully restore the replication factor of all records affected by the failure at a rate of 5-10GB per second.
Rebuilding coordination is fully distributed and is performed over an internal metadata log that we call the event log.
The local log store
The separation of sequencing and storage helps allocate the aggregate CPU and storage resources of the cluster to match the changing, sometimes spiky workload. However, the per-node efficiency of a distributed data store is largely determined by its local storage layer. In the end multiple record copies must be saved on non-volatile devices, such as hard drives or SSDs. RAM-only storage is impractical when storing hours worth of records at 100MBps+ per node. When backlog duration is measured in days (not an uncommon requirement at Facebook) hard drives are far more cost efficient than flash. This is why we designed the local storage component of LogDevice to perform well not only on flash with its huge IOPS capacity, but also on hard drives. Commodity HDDs can push a respectable amount of sequential writes and reads (100-200MBps), but top out at 100-140 random IOPS.
We called the local log store of LogDevice LogsDB. It is a write-optimized data store designed to keep the number of disk seeks small and controlled, and the write and read IO patterns on the storage device mostly sequential. As their name implies write-optimized data stores aim to provide great performance when writing data, even if it belongs to multiple files or logs. The write performance is achieved at the expense of worse read efficiency on some access patterns. In addition to performing well on HDDs LogsDB is particularly efficient for log tailing workloads, a common pattern of log access where records are delivered to readers soon after they are written. The records are never read again, except in rare emergencies: those massive backfills. The reads are then mostly served from RAM, making the reduced read efficiency of a single log irrelevant.
LogsDB is a layer on top of RocksDB, an ordered durable key-value data store based on LSM trees. LogsDB is a time-ordered collection of RocksDB column families, which are full-fledged RocksDB instances sharing a common write-ahead log. Each RocksDB instance is called a LogsDB partition. All new writes for all logs, be it one log or a million, go into the most recent partition, which orders them by (log id, LSN), and saves on disk in a sequence of large sorted immutable files, called SST files. This makes the write IO workload on the drive mostly sequential, but creates the need to merge data from multiple files (up to the maximum allowed number of files in a LogsDB partition, typically about 10) when reading records. Reading from multiple files may lead to read amplification, or wasting some read IO.
LogsDB controls read amplification in a way uniquely suited for the log data model with its immutable records identified by immutable LSNs monotonically increasing with time. Instead of controlling the number of sorted files by compacting (merge-sorting) them into a bigger sorted run LogsDB simply leaves the partition alone once it reaches its maximum number of SST files, and creates a new most recent partition. Because partitions are read sequentially, at no time the number of files to read concurrently will exceed the maximum number of files in a single partition, even if the total number of SST files in all partitions reaches tens of thousands. Space reclamation is performed efficiently by deleting (or in some cases infrequently compacting) the oldest partition.
Use cases and future work
LogDevice has become a versatile solution for a variety of logging workloads at Facebook. The following are just a few examples. Scribe is one of the larger users of LogDevice by total throughput, exceeding at peak a terabyte per second of ingest, delivered reliably and with the possibility of replay. Scribe provides a fire-and-forget write API with delivery latency expectations on the order of seconds. LogDevice clusters running Scribe are tuned for per-box efficiency, rather than low end-to-end latency or append latency. Maintaining secondary indexes on TAO data is another important use case for LogDevice. Here the throughput is not as large as with Scribe, but strict record ordering per log is important, and the expected end-to-end latency is on the order of 10ms. This required very different tuning. Another interesting example is machine learning pipelines, which use LogDevice for delivering identical event streams to multiple ML model training services.
LogDevice is under active development. It is written in C++ and has few external dependencies. New areas that we are currently exploring include disaggregated clusters, where storage and CPU-intensive tasks are handled by servers with different hardware profiles, support for very high volume logs, and efficient server-side filtering of records by an application-supplied key. Together these features will improve the hardware efficiency of LogDevice clusters, and will provide a scalable load distribution mechanism for the consumers of high throughput data streams.
UPDATE: LogDevice is now open sourced and available on github.











