
Five years ago, we created the Facebook AI Research (FAIR) group to advance the state of the art of AI through open research for the benefit of all — it’s an effort to understand the nature of intelligence so that we might create intelligent machines. Since then, FAIR has learned a lot and grown into an international research organization with labs in Menlo Park, New York, Paris, Montreal, Tel Aviv, Seattle, Pittsburgh, and London. AI has become so central to Facebook that FAIR is now part of a larger Facebook AI organization that works on all aspects of AI R&D, from fundamental research to applied research and technology development.
FAIR has applied an open model to all aspects of our work, collaborating broadly with the community. Our teams publish cutting-edge research early and often, and open-source our research code, data sets, and tools like PyTorch, fastText, FAISS, and Detectron where possible. The approach has been successful for advancing the state of AI research. This year, FAIR’s researchers have won recognition, including Best Paper awards, at ACL, EMNLP, CVPR, and ECCV, and Test of Time awards at ECCV, ICML, and NeurIPS. We know working in the open allows everyone to make faster progress on AI.
Making machines truly intelligent is a scientific challenge as well as a technological and product engineering challenge. A significant part of FAIR’s research focuses on fundamental questions about the keys to reasoning, prediction, planning, and unsupervised learning. And in turn, these areas of investigation require better theoretical understanding in fields such as generative models, causality, high-dimensional stochastic optimization, and game theory. These long-term research explorations are required to unlock the full future potential of artificial intelligence. Of all the projects we’ve tackled over the past five years, we’ve picked a handful that show how FAIR has approached its mission, contributed to our field, and made an impact on the world.
Memory networks
In 2014, researchers at FAIR identified an intrinsic limitation in neural networks — long-term memory. Though neural nets could learn during the process of training on data sets, once these systems were in operation they were typically unable to store new information to help solve a particular task later on. So we developed a new class of learning-model-enabled machines that remembered enough of their interactions to answer general knowledge questions and refer to previous statements in a conversation. In our initial 2014 paper on this approach, we tested this by having a memory-enabled network answer questions about the plot of the Lord of the Rings series, based on a short summary provided to it. The system was able to learn simple linguistic patterns and generalize the meanings of unknown words, correctly answering, for example, that at the end of the story Frodo was in the shire and the ring was in Mount Doom.
FAIR continued to develop this approach over the next two years, extending the research and exploring related areas. With StackRNN, the team augmented an RNN with push-pop stacks that could be trained from sequences in an unsupervised manner. With bAbl, the team built data sets of question-answering tasks to help benchmark performance in text understanding. bAbI is now part of the open source project ParlAI that includes thousands of dialogue examples, ranging from responses to restaurant-reservation requests to answers about movie casts. We also iterated on memory network architectures, making them increasingly useful for real-world applications. These updates included end-to-end memory networks, which allowed them to work with less supervision, and then key-value memory networks, which could be trained by generalizing from completely unsupervised sources, such as Wikipedia entries.
Self-supervised learning and generative models
It has long been one of FAIR’s priorities to scale up AI by exploiting large amounts of unlabeled data through self-supervised learning (SSL). With SSL, a machine can learn abstract representations of the world by being fed unlabeled images, video, or audio. An example of SSL is showing video clips to a machine and training it to predict future frames. By learning to predict, the machine captures knowledge about how the world works and learns good abstract representations of it. Using SSL, machines learn by observation, a bit like human and animal babies do, and accumulate large quantities of background knowledge about the world. The hope is that a form of common sense could emerge. Acquiring predictive world models is also key to building AI systems that can reason, predict the consequences of their actions, and act in the real world.
In 2014, our friends from MILA at Université de Montréal proposed a new unsupervised learning method called generative adversarial networks (GANs). We were immediately fascinated by the potential applications of self-supervised learning. But as promising as GANs looked, they had been demonstrated only on “toy” problems. Starting in 2015, we published a series of papers that were instrumental in convincing the research community that GANs really worked. GANs are used to train machines to make predictions under uncertainty by pitting two neural networks against each other. In a typical GAN architecture, the generator network produces data — such as an image or a video frame — from a bunch of random numbers (and perhaps past video frames). Meanwhile, the discriminator network has to differentiate between real data — real images and video frames — and the generator’s “false” outputs. This ongoing contest optimizes both networks and leads to increasingly better predictions.
Each of our papers focused on different variants of GANs, including image generation in Deep Convolutional Generative Adversarial Networks (DCGANs) and Laplacian Adversarial Networks (LAPGANs), and video prediction in Adversarial Gradient Difference Loss Predictors (AGDLs). But our collective contribution was to show that GANs could “invent” realistic-looking images of, for example, nonexistent bedrooms, faces, or dogs.

This example shows a series of fashion designs created by generative networks.
Other researchers have since picked up on our work in GANs, using them to produce stunning high-resolution images. But GANs are notorious for being very difficult to tune and for often failing to converge. So FAIR has explored ways to make GANs more reliable by focusing on understanding adversarial training at the theoretical level. In 2017, we introduced the Wasserstein GAN (WGAN) method, which proposed a way to make the discriminator “smooth” and more efficient, in order to tell the generator how to improve its predictions. The WGAN was essentially the first GAN whose convergence was robust on a wide range of applications. This avoided the need to balance the output of discriminators and generators as the system is optimized, which results in significantly more learning stability, particularly for high-resolution image generation tasks.
Since then, FAIR researchers and Facebook engineers have used adversarial training methods for a range of applications, including long-term video prediction and the creation of fashion pieces. But the really interesting part of GANs is what they mean for the future. As a brand-new technique that wasn’t available to us even a few years ago, it opens up new opportunities to generate data in areas where we have little data. It will likely be a key tool on our quest to build machines that can learn on their own.
Text classification that scales
Text understanding isn’t a single task but a sprawling matrix of subtasks that organize words, phrases, and entire data sets of language into a format that machines can process. But before much of that work can take place, the text itself has to be classified. Years ago, NLP models such as word2vec classified text through extensive, word-based training, with the model assigning a distinct vector to each word in its training data set. For Facebook, the status quo was simply too slow and too dependent on fully supervised data. We needed text classification that could eventually work with hundreds or even thousands of languages, many of which don’t lend themselves to extensive data sets. And the system needed to scale across the entire range of text-based features and services, as well as our NLP research.
So in 2016 FAIR built fastText, a framework for rapid text classification and learning word representations that takes into account the larger morphology of the words it classifies. In a paper published in 2017, FAIR proposed a model that assigns vectors to “subword units” (e.g., sequences of 3 or 4 characters) rather than to whole words, allowing the system to create representations for words that didn’t appear in training data. The end result was a model whose classifications can scale to billions of words, learning from novel, untrained words while also training significantly faster than typical deep learning classifiers. In some cases, training that had taken several days with previous models was finished in a few seconds with fastText.
FastText has proved to be a vital contribution to the study and application of AI-based language understanding, and it’s now available in 157 languages. The original paper has been cited more than a thousand times in other publications, and fastText remains one of the most commonly used baselines for word embedding systems. Outside of Facebook, fastText has been used for a diverse array of applications, ranging from the familiar, such as suggesting message replies, to the exotic — an “algorithmic theater” production called The Great Outdoors, which used fastText to help select and order public internet comments that would become the script for each performance. The framework is deployed at Facebook to classify text across 19 languages, and it’s used in tandem with DeepText for translation and natural language understanding.
Cutting-edge translation research
Fast, accurate, and flexible translation is a key component of helping people around the world to communicate. So, in the early days of FAIR, we set out to find a new approach that would outperform statistical machine translation, which was then the state-of-the-art method. It took three years of work to build a CNN-based neural machine translation (NMT) architecture with the right combination of speed, accuracy, and learning. (FAIR published a paper in 2017 detailing its work.) In our experiments, this approach resulted in a 9x increase in speed over RNNs while maintaining state-of-the-art accuracy rates.

Not only are our multi-hop CNNs easier to train on more limited data sets, but they’re also better able to understand misspelled or abbreviated words, such translating “tmrw” as “mañana.” Overall, the NMT transition has improved accuracy by an average of 11 percent and sped delivery of translations by 2.5x. And in addition to improving our own systems, we open-sourced the code and models for fairseq, the sequence-to-sequence modeling toolkit that we used for our CNN-based system.
To sidestep the need for vast training data sets for translations (often called corpora), we’re also pursuing other methods, such as multilingual embeddings, which can enable training across multiple languages. Last year, we released MUSE, an open source Python library that provides two different methods for learning multilingual embeddings: a supervised approach, using the 110 bilingual dictionaries included in the release, and a newer, unsupervised method that allows new bilingual dictionaries to be built between two languages without parallel corpora. We followed this with an EMNLP award-winning paper demonstrating a dramatic improvement in unsupervised training for translation of full sentences.

Two-dimensional word embeddings in two languages (left) can be aligned via a simple rotation (right). After the rotation, word translation is performed via nearest neighbor search.
By sharing research and resources like fairseq and MUSE, we’re encouraging others to take advantage of faster, more accurate, and more versatile translation techniques, whether for research purposes or production applications.
AI tools that level everybody up
Progress in AI depends not only on breakthrough ideas but also on having powerful platforms and tools for testing and then implementing them. FAIR has prioritized building these systems and sharing them with the world. In 2015, we open-sourced the Torch deep learning modules created by FAIR to speed up training of larger neural nets. We released Torchnet in 2016 to make it easier for the community to rapidly build effective and reusable learning systems. Soon after, we introduced Caffe2, our modular deep learning framework for mobile computing that is now running neural nets on more than 1 billion phones around the world. And then we collaborated with Microsoft and Amazon to release ONNX, a common representation for neural networks that makes it simple to move between frameworks as needed.
In particular, our work on PyTorch demonstrates FAIR’s commitment to rapid iteration, meaningful impact, open systems, and collaboration with the AI community. PyTorch began as a small effort with just a handful of FAIR researchers. Rather than build a completely new deep learning framework, we chose to build on top of the Torch open source library, and we integrated with acceleration libraries from Intel and NVIDIA to maximize speed. We announced PyTorch at the beginning of 2017 — less than two years ago! It’s now the second-fastest-growing open source project on GitHub and the framework of choice for AI developers around the globe. In October, hundreds of members of the AI community attended the first PyTorch Developers Conference to hear presentations from Caltech, FAIR, fast.ai, Google, Microsoft, NVIDIA, Tesla, and many others. And now the release of PyTorch 1.0 integrates the modular, production-oriented capabilities of Caffe2 and ONNX to provide a seamless path from research prototyping to production deployment, with deep integration with cloud services and technology providers.
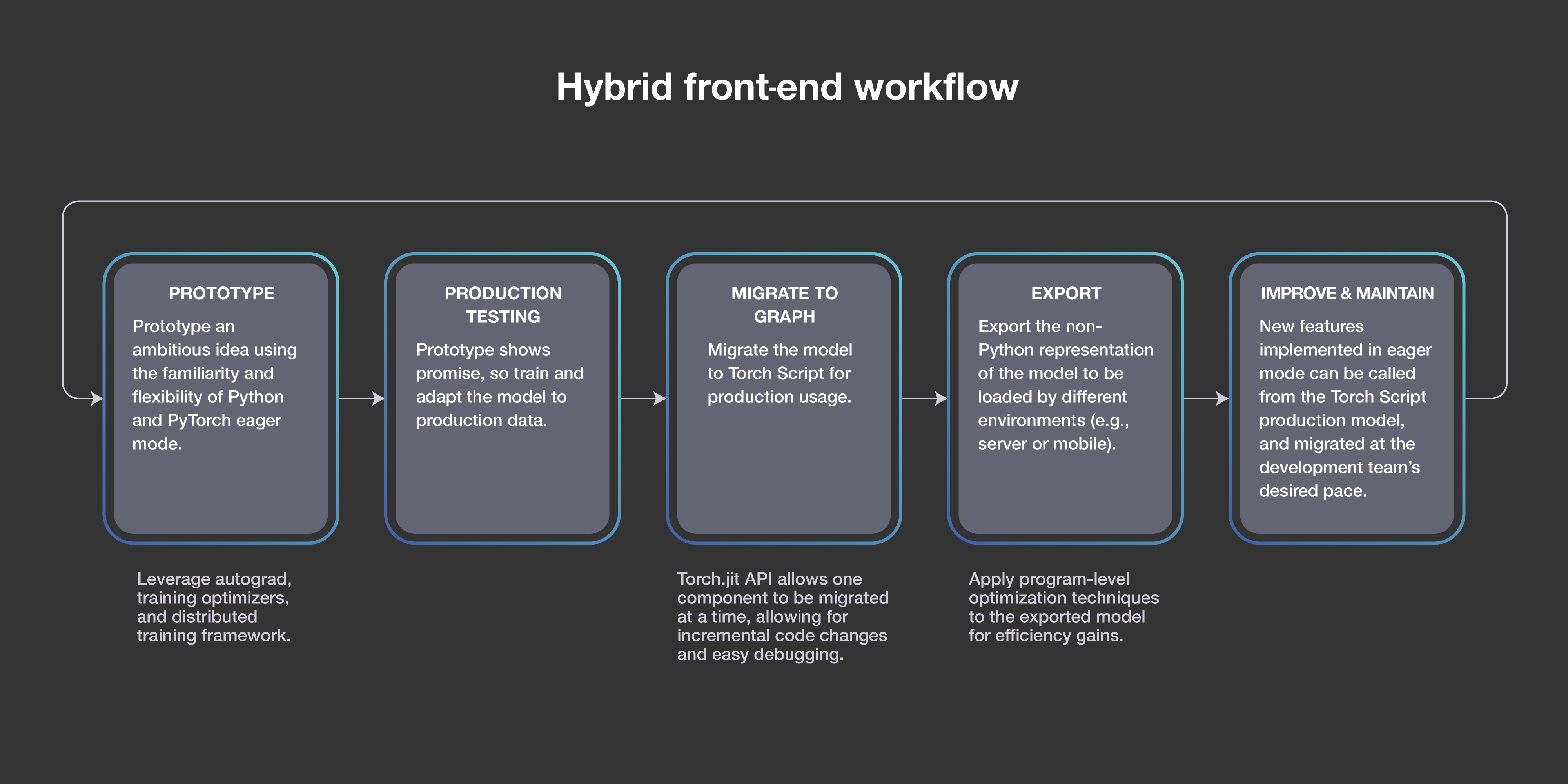
PyTorch is integrated in Facebook products that are used by billions of people, as well as in FAIR research projects such as fairseq(-py), which accelerates translations by 80 percent over the previous version. PyTorch is also used by ELF OpenGo, our reinforcement learning bot; our EmbodiedQA work; and our successful effort to train image recognition networks on billions of public images with hashtags. And beyond Facebook, PyTorch powers projects from AllenNLP to NYU professor Dr. Narges Razavian’s work to use AI to improve early detection of disease. And now Udacity and fast.ai are helping even more people get going with PyTorch.
Whereas PyTorch made it faster and easier to take models from research to production, our work on Facebook AI Similarity Search (FAISS) has accelerated large-scale search. FAISS began as an internal research project to better utilize GPUs for identifying similarities related to user preferences, and it is now the fastest available library of its kind and able to leverage billion-scale data sets. FAISS has already opened up possibilities for recommendation engines and AI-based assistant systems. We released it as an open source library last year, and FAISS has been widely adopted by the developer community, with more than 5,000 GitHub stars and integration into NVIDIA’s GPU-accelerated scikit-learn library, cuML.
A new benchmark for computer vision
Seeking to understand the nature of intelligence is a study in multisensory modalities, but the story of FAIR’s past five years is really bookended by advancements in computer vision. Before FAIR was born, there was a small team of AI specialists at Facebook seeking to better understand how pixels represent people in images, so that the right photos might be surfaced for people at the right times. Fast-forward to 2017, and FAIR researchers had won the International Conference on Computer Vision Best Paper for Mask R-CNN, combining the best of computer vision worlds: object detection with semantic segmentation.
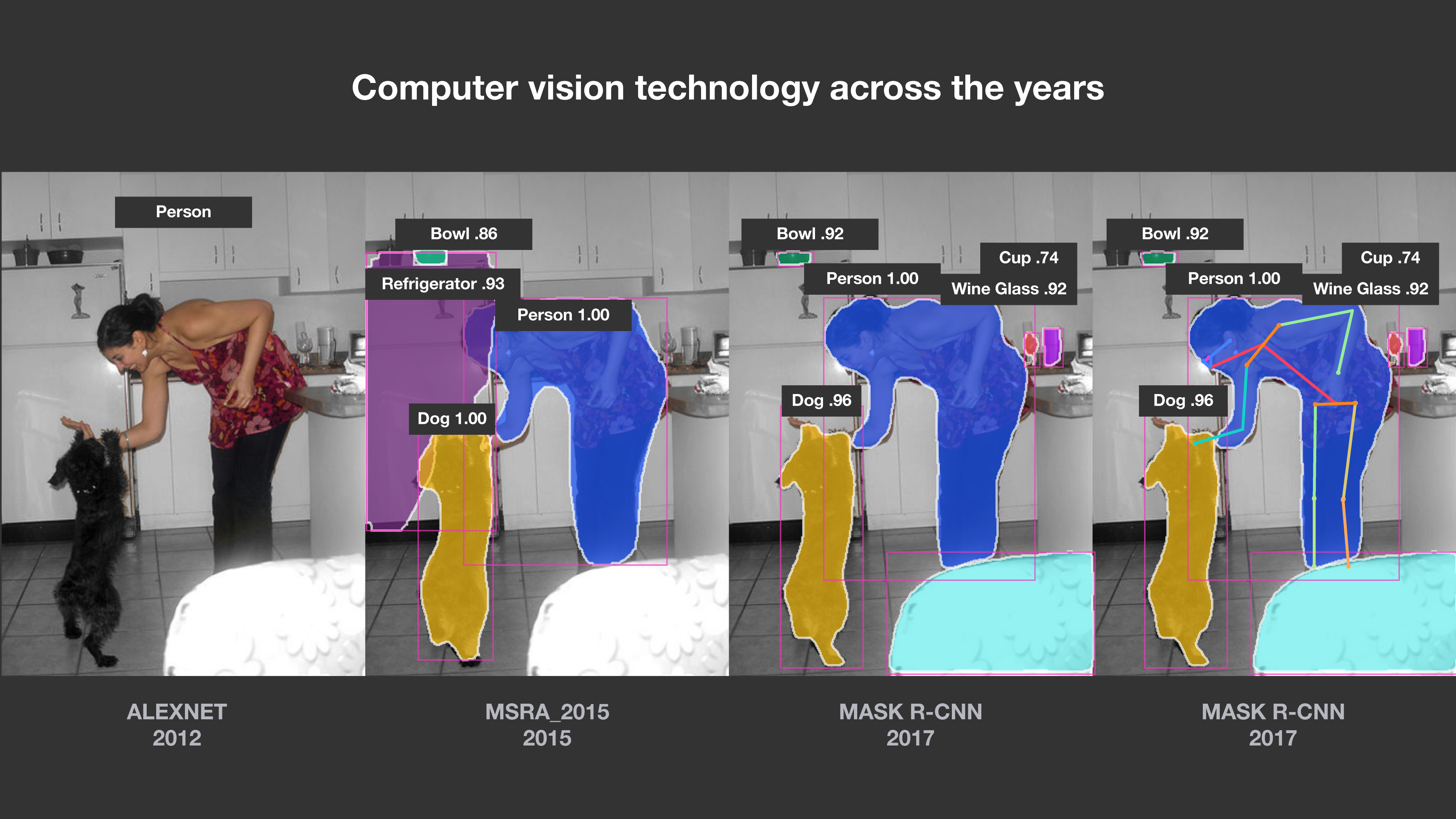
As the paper stated, “Without bells and whistles, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners.” The work rapidly became the basis for computer vision research in the broader AI community. The technology was then integrated into our open source Detectron system, bringing the meta algorithm’s intuitive ease of use, speed, and accuracy to researchers everywhere.
This foundational work now underpins a myriad of Facebook’s current systems, such as automatic alt text to help the visually impaired and tools that detect objectionable content. It’s also groundwork for future applications: AR features across our platforms and Smart Camera in Portal have roots in this work. This research continues, with the focus moving to video, where our DensePose project will help our systems understand video content as well as they understand photos.
Demonstration of DensePose creating a 3D surface on top of people as they move.
Image understanding: Faster training and bigger data sets
Computer vision isn’t the only area where FAIR has looked to address scale challenges. FAIR partnered with Facebook’s Applied Machine Learning (AML) team to tackle the limitations of training speed and training set sizes, as well as the lack of supervised data sets. In a paper published earlier this year, the team at AML discussed how they trained image recognition networks on large sets of public images with hashtags, the biggest of which included 3.5 billion images and 17,000 hashtags. It was an order of magnitude more than any previous published work and the results were the best published results for the industry to-date: 85.4% accuracy.
This breakthrough was made possible by FAIR’s research on training speed — FAIR was able to train ImageNet an order of a magnitude faster that previous state of the art. They got the training time down to under one hour, showing how to perform SGD training with minibatch sizes an order of magnitude larger than were previously considered practical. In their words: “To achieve this result, we adopt a linear scaling rule for adjusting learning rates as a function of minibatch size and develop a new warmup scheme that overcomes optimization challenges early in training.”
With this improvement in training speed, we were able to perform directed research on weakly supervised learning on bigger data sets than was previously possible. Both results show the clear value of a partnership between FAIR and AML. When the science of solving AI is buttressed by practical research and application in production, we see rapid, state-of-the-art results.
The future of FAIR
When we created FAIR, our ultimate goal was to understand intelligence, to discover its fundamental principles, and to make machines significantly more intelligent. Our goal has not changed. We’re continuing to expand our research efforts into areas such as developing machines able to acquire models of the world through self-supervised learning, training machines to reason, and training them to plan and conceive complex sequences of actions. That is one reason we are working on robotics, visual reasoning, and dialogue systems. We’ve described some of the more concrete projects that show how far we’ve come, but we still have far to go in scientific and technological advances to make machines sufficiently intelligent to help people in their daily lives.











