
WHAT THE RESEARCH IS:
A new approach to pretraining cross-lingual models for natural language processing (NLP) tasks. Our method delivers a significant improvement over the previous state of the art in both supervised and unsupervised machine translation, as well as in cross-lingual text classification of low-resource languages. For example, we set new accuracy marks for unsupervised German-English machine translation and supervised Romanian-English translation. Specifically, this pretraining technique pushes the performance of unsupervised machine translation systems closer to that of supervised ones and even surpasses them on low-resource language pairs, such as Romanian-English.
We are providing code and pretrained models to the community so that others can use and build upon this work.
HOW IT WORKS:
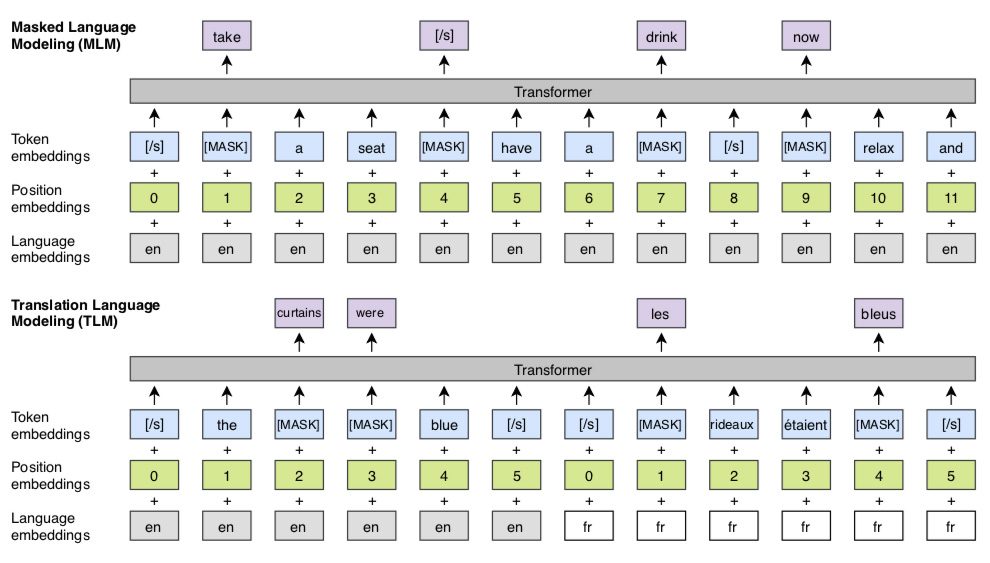
The masked language modeling (MLM) objective is similar to the one of Devlin et al. (2018) but with continuous streams of text as opposed to sentence pairs. The translation language modeling (TLM) objective extends MLM to pairs of parallel sentences. To predict a masked English word, the model can attend to both the English sentence and its French translation and is encouraged to align English and French representations. Position embeddings of the target sentence are reset to facilitate the alignment.
We developed a translation language modeling (TLM) method that is an extension of masked language modeling (MLM), a popular and successful technique that trains NLP systems by making the model deduce a randomly hidden or masked word from the other words in the sentence. In our work, we concatenate parallel sentences in a corpora consisting of two different languages. Then the model learns by analyzing text in either language or in both of them to infer the masked word.
This approach has allowed us to improve performance for zero-shot cross-lingual classification, to improve initialization of supervised and unsupervised neural machine translation (NMT) systems, and to create unsupervised cross-lingual word embeddings. The diagram above illustrates how our model works.
WHY IT MATTERS:
Pretraining — using unlabeled data sets to help an NLP model perform a particular task — has been shown to be very effective in improving results. This work is the first to demonstrate how cross-lingual pretraining can help produce even greater improvements. Our approach is a significant step for cross-lingual understanding, which is essential for providing better NLP systems for low-resource languages. It has also shown improvements in a wide range of NLP tasks. For instance, our model improves the performance of unsupervised machine translation systems by up to 9 BLEU (bilingual evaluation understudy, a common machine translation metric), even surpassing the performance of supervised approaches on language pairs with few translation resources. In cross-lingual classification (XNLI), our approach beats the state of the art across all languages by an average of 5 percent. It is also the first time that a cross-lingual model has outperformed monolingual models on high-resource languages.
This work follows a series of recent achievements by FAIR on cross-lingual text representations (including MUSE, UMT, LASER, and XNLI).
READ THE FULL PAPER:
https://arxiv.org/abs/1901.07291
The code for our approach is publicly available here.











